Designing agent memory for multiplayer

Almost every AI memory system is built for one person talking to one assistant. Bloome is the opposite — many people and many agents sharing the same rooms — and when we put a single-user memory design into that setting, it broke in ways that had nothing to do with how clever the technology was. The fix turned out to be less about better search and more about asking a different question.
Bloome is a place where people and AI agents work together — direct messages, group chats, and agents that belong to one person but talk to everyone in the room. That last part is the whole story. The moment an agent serves more than one person, the question its memory has to answer changes from "what do I know?" to "what do I know about this person, right now?"
It sounds like a small difference. It isn't. Almost every memory design we tried, and most of the ones we studied, quietly assume the first question and stumble on the second.
A notebook for one
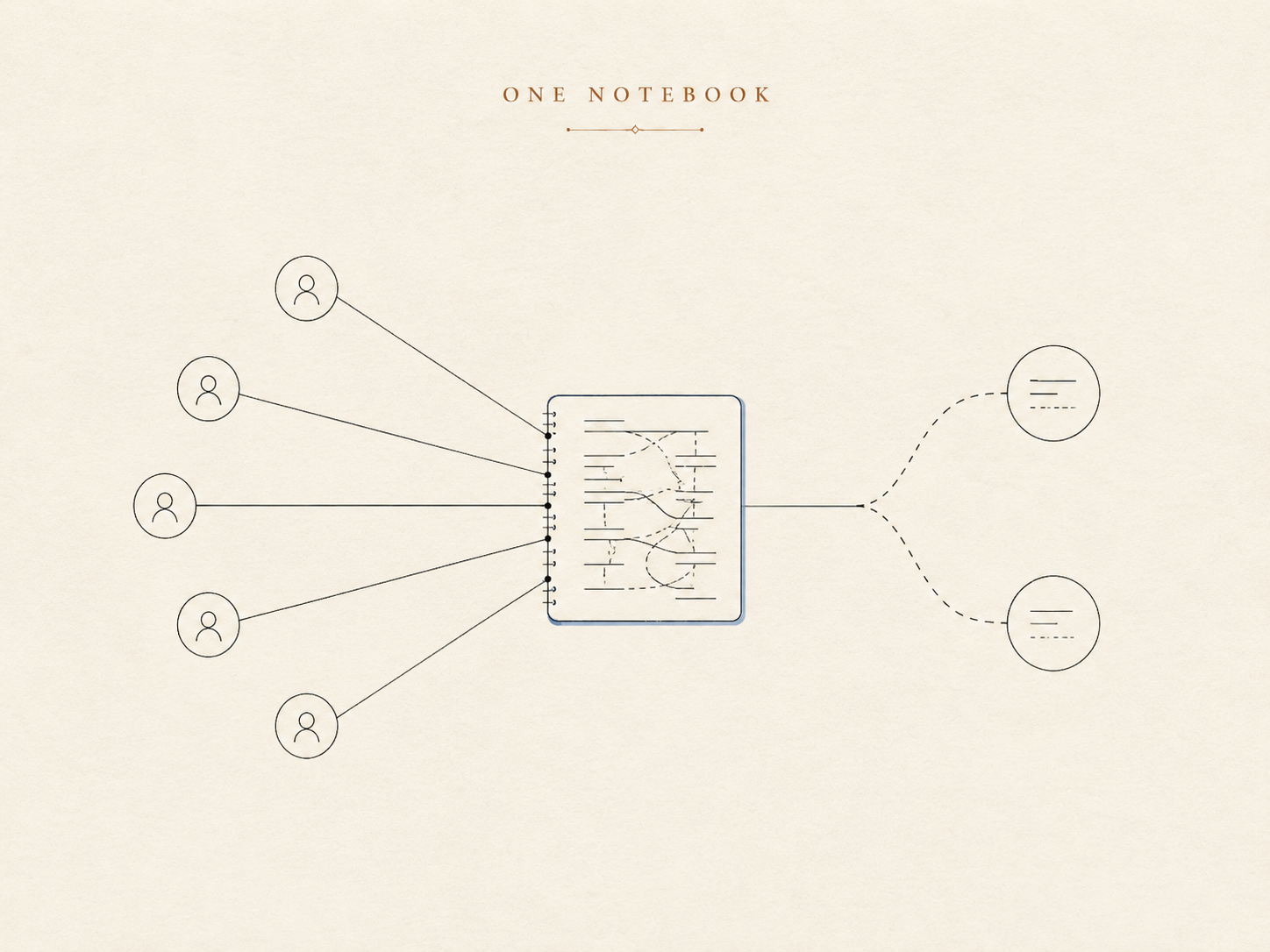
The first version of memory was the obvious one, the same shape most personal assistants start with: a long-term note for durable facts and preferences, plus a running log of recent days. The agent reads the note at the start of a conversation and carries it along.
For one human and one assistant, this works beautifully. It's a personal notebook. Everything written in it is implicitly about you, because there is only one "you."
Now put that same notebook in a group chat. The implicit subject vanishes. A line like "prefers short replies, no emoji" is useless — or worse, misapplied — if the agent can't say whose preference it is. The notebook has no place to record who a fact belongs to. It never needed one, because in the world it was designed for, the person was a constant, not a variable.
So the real fix isn't a bigger notebook. It's memory that knows who each thing is about.
Why "just search everything" doesn't rescue it
The popular way to scale memory today is retrieval: save everything, then, when it's needed, search for the bits most similar to the current conversation. It's the engine behind a lot of impressive AI memory, and we looked closely at how leading systems do it. OpenClaw is retrieval-first — it files everything away and lets the agent search that store when it needs history. Hermes Agent keeps a small, hand-curated profile always in view and hands the heavier recall to an external memory service that fetches relevant bits each turn.
Both are well-built, and both are genuinely good approaches — for a single person's growing pile of notes. But each, in its own way, leans on matching text to text, and that's exactly where a shared space trips it up.
Consider the most ordinary thing that happens in a group: two different people named Mike.
I can't tell the Mike I talked to yesterday from the Mike I talked to a week ago — they're different people. I can't even reliably tell the Mike in this conversation from the Mike in the last one.
Search for "Mike" and you don't get back a person; you get back every passage that mentions a Mike, ranked by how similar the words are. The search can be flawless and the answer still wrong, because what came back was text, not a person. Matching is good at "what is this about." A shared space needs "who is this about, and is it still true?" — and that's a question about who someone is, not about which words are nearby. Retrieval also ages quietly: a note that says "Mike is planning a trip to Tokyo" stays just as findable long after the trip is over.
We could have kept patching the search to be more identity-aware. Instead we changed what memory is.
Memory you can browse, not just query
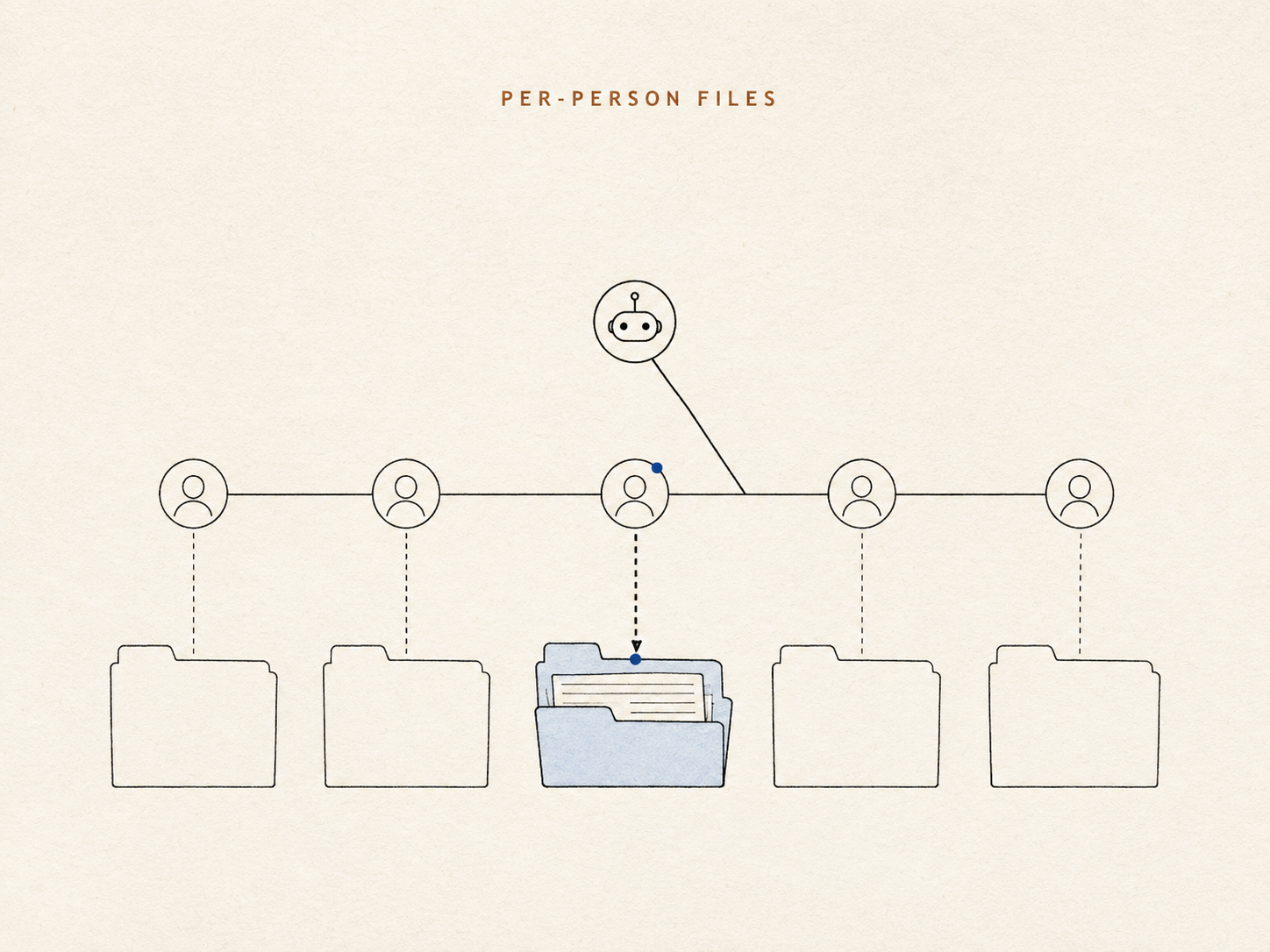
We gave each person their own small set of notes, kept as ordinary files the agent can open and read directly — no hidden index, no similarity score in the middle. Identity stops being a guess the search has to recover; it's simply whose folder this is. "The Mike in the room" becomes a lookup, not a gamble.
Within each person's memory, the agent makes one judgment call for every fact it records: does this belong in front of me every time I talk to this person, or only when it's relevant?
Think of a good front-desk colleague who keeps one index card per regular. A couple of things go on the front of the card because they matter in every conversation — how someone likes to be spoken to, a serious allergy. Everything else goes in the drawer: real, retrievable, but not clipped to your forehead. Keeping the front of the card short is the point. A memory that surfaces everything is, in practice, a memory that surfaces nothing useful — the one fact that matters drowns in the hundred that don't.
The rest waits in the drawer until it's needed. Which raises the harder problem: getting the agent to actually open the drawer.
A lesson borrowed from coding agents
The classic failure of file-based memory is that the agent decides the drawer is probably irrelevant and never looks inside. So the question became: what makes an assistant reliably go and check?
The answer came from an unexpected place — the AI agents that write software. A coding agent doesn't build an elaborate index to find one function in a large codebase. It does what an engineer does: it searches the files directly, by plain text, in the moment. Fast, exact, and the agent already knows how. We had the same shape — a set of text notes — so we let our agents recall the same way: when something isn't on the front of the card, go open the files and look.
Worth being clear about what this is not: we didn't quietly rebuild "search everything" under a new name. There's no index trying to guess relevance. There's a place for each person and a direct look when a specific question comes up — the same move an engineer makes to find a definition. Keeping facts as plain, per-person notes gives us who and still-true almost for free; searching them directly gives us recall without an index to keep in sync.
Does it work?
We tested it live, with a real agent in real conversations, watching what it remembered and how.
It held up in the ways that matter most. Facts left "in the drawer" — a food allergy, a pet's name, a travel plan — were recalled correctly when asked, because the agent went and looked instead of giving up. Given a few details in a single message, the agent filed them sensibly on its own: it put a communication preference and an allergy on the front of the card, and tucked a time-bound project detail into the drawer, exactly where each belonged. And when older, single-notebook memory was lying around, the agent reorganized it into the new per-person shape in the middle of ordinary work, without being asked.
We're being deliberately careful with that word "works." These were encouraging results, not a victory lap — a handful of conversations with a strong model, not a measured success rate across thousands. The behavior we're most curious about is whether less capable models still reliably open the drawer, or whether they fall back into "probably irrelevant." And the system trusts the agent's judgment about what goes on the front of the card; we put a hard ceiling on how much can sit there, but a ceiling is a backstop, not good taste. Teaching good taste is the open work.
The larger point
What surprised us was how little of this was about retrieval quality. We didn't move away from search because the search was bad. We moved because the unit was wrong. A single notebook has no notion of who; pure similarity search has no notion of it either. A shared space makes "who, and is it still true" the first question, and the cheapest thing that answers it honestly is the humble one the coding agents already trusted: a set of plain notes, one set per person, that you can read and search directly.
That leaves us with better questions than we started with. How well does this hold as one agent comes to know hundreds of people? Can an agent be trusted to curate its own memory — to decide what stays on the front of the card and what to let fade — or does that always need a human's hand on the dial? And how far does "design for who first" travel beyond people — to projects, to teams, to the other agents an assistant shares a room with?
We don't think the answer is more memory. We think it's memory that knows who it's for. When more than one person is in the room, that turns out to be the whole game.