Design de memória de agente para multiplayer

Quase todo sistema de memória de IA é feito para uma pessoa falando com um assistente. O Bloome é o oposto — muitas pessoas e muitos agentes dividindo as mesmas salas — e quando colocamos um design de memória feito para um único usuário nesse cenário, ele quebrou de formas que não tinham nada a ver com o quão inteligente era a tecnologia. A solução acabou tendo menos a ver com busca melhor e mais com fazer uma pergunta diferente.
O Bloome é um lugar onde pessoas e agentes de IA trabalham juntos — mensagens diretas, group chats e agentes que pertencem a uma pessoa mas conversam com todo mundo na sala. É essa última parte que muda tudo. No momento em que um agente atende mais de uma pessoa, a pergunta que a memória dele precisa responder deixa de ser "o que eu sei?" e passa a ser "o que eu sei sobre esta pessoa, agora?"
Parece uma diferença pequena. Não é. Quase todo design de memória que tentamos, e a maioria dos que estudamos, assume silenciosamente a primeira pergunta e tropeça na segunda.
Um caderno para uma pessoa só
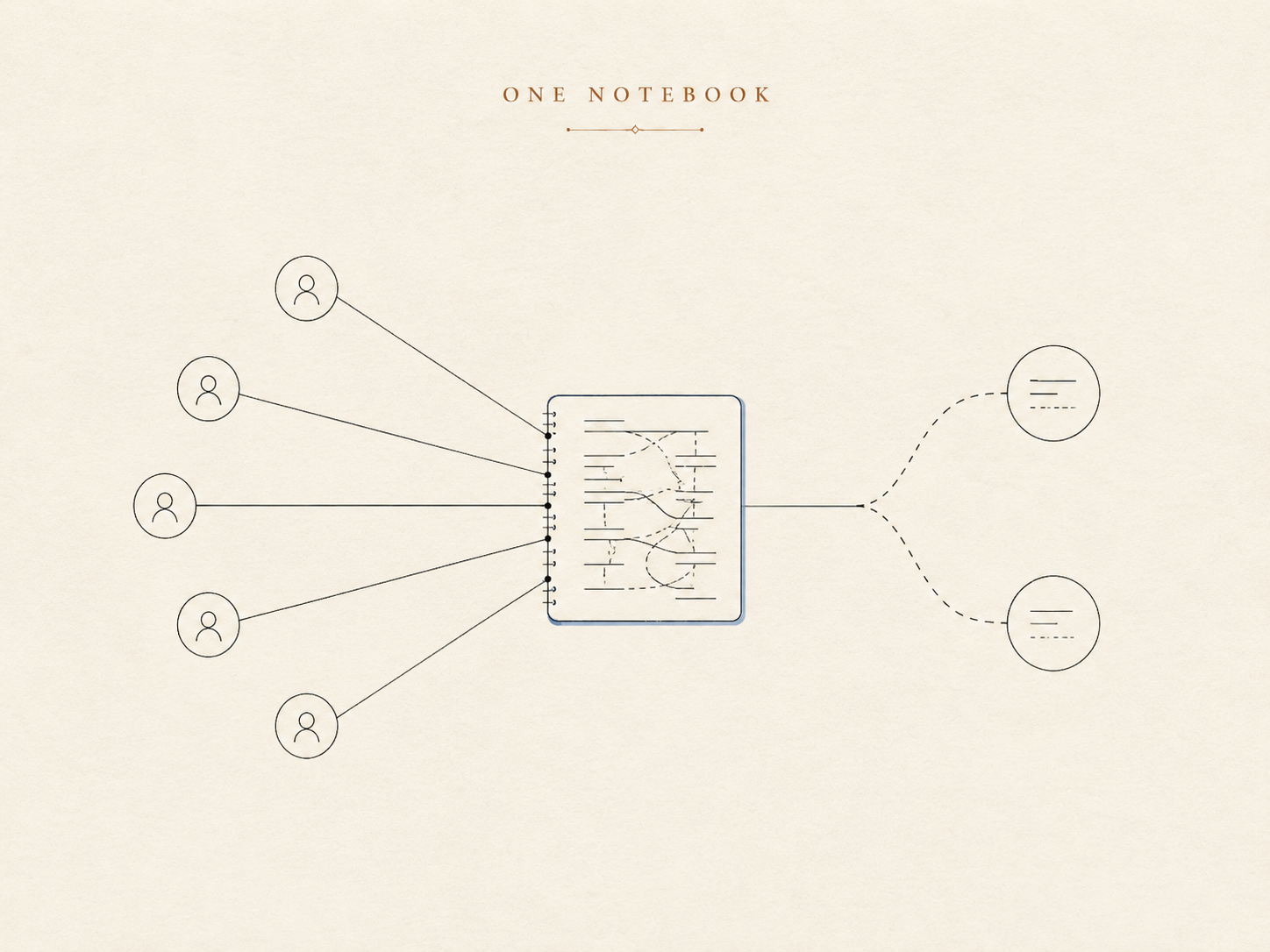
A primeira versão da memória foi a óbvia, o mesmo formato com que a maioria dos assistentes pessoais começa: uma nota de longo prazo para fatos e preferências duráveis, mais um registro corrido dos dias recentes. O agente lê a nota no começo de uma conversa e a carrega consigo.
Para um humano e um assistente, isso funciona lindamente. É um caderno pessoal. Tudo o que está escrito nele é implicitamente sobre você, porque só existe um "você".
Agora coloque esse mesmo caderno em um group chat. O sujeito implícito desaparece. Uma linha como "prefere respostas curtas, sem emoji" é inútil — ou pior, aplicada errada — se o agente não consegue dizer de quem é essa preferência. O caderno não tem onde registrar a quem um fato pertence. Ele nunca precisou disso, porque no mundo para o qual foi projetado a pessoa era uma constante, não uma variável.
Então a solução de verdade não é um caderno maior. É uma memória que sabe sobre quem é cada coisa.
Por que "é só buscar tudo" não resolve
A forma popular de escalar memória hoje é a recuperação (retrieval): salvar tudo e, quando precisar, buscar os trechos mais parecidos com a conversa atual. É o motor por trás de muita memória de IA impressionante, e olhamos de perto como os principais sistemas fazem isso. O OpenClaw é retrieval-first — arquiva tudo e deixa o agente buscar nesse repositório quando precisar do histórico. O Hermes Agent mantém um perfil pequeno e curado à mão sempre à vista e delega a recuperação mais pesada a um serviço externo de memória que busca os trechos relevantes a cada turno.
Os dois são bem construídos e os dois são abordagens genuinamente boas — para a pilha crescente de anotações de uma única pessoa. Mas cada um, à sua maneira, se apoia em casar texto com texto, e é exatamente aí que um espaço compartilhado os derruba.
Considere a coisa mais comum que acontece em um grupo: duas pessoas diferentes chamadas Mike.
Não consigo diferenciar o Mike com quem falei ontem do Mike com quem falei uma semana atrás — são pessoas diferentes. Não consigo nem distinguir com confiança o Mike desta conversa do Mike da conversa anterior.
Busque por "Mike" e você não recebe de volta uma pessoa; recebe todos os trechos que mencionam um Mike, ordenados por quão parecidas são as palavras. A busca pode ser impecável e a resposta ainda estar errada, porque o que voltou foi texto, não uma pessoa. Casar texto é bom para "sobre o que é isto". Um espaço compartilhado precisa de "sobre quem é isto, e ainda é verdade?" — e essa é uma pergunta sobre quem alguém é, não sobre quais palavras estão por perto. A recuperação também envelhece em silêncio: uma nota que diz "Mike está planejando uma viagem para Tokyo" continua tão fácil de encontrar muito depois de a viagem ter acabado.
Poderíamos ter continuado remendando a busca para ela ficar mais consciente de identidade. Em vez disso, mudamos o que a memória é.
Memória que você pode folhear, não só consultar
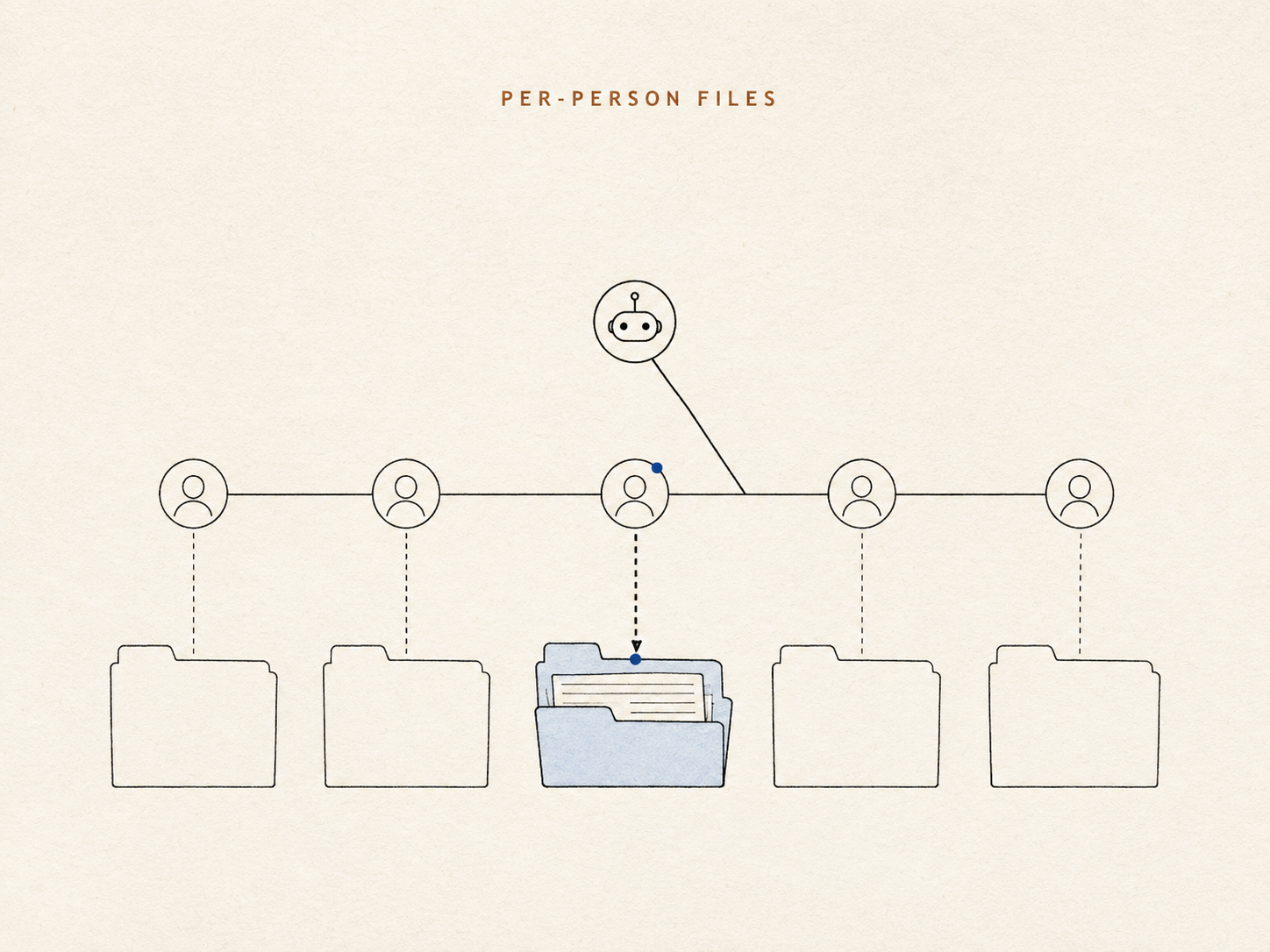
Demos a cada pessoa seu próprio conjunto pequeno de anotações, mantido como arquivos comuns que o agente pode abrir e ler diretamente — sem índice escondido, sem pontuação de similaridade no meio. A identidade deixa de ser um palpite que a busca precisa recuperar; é simplesmente de quem é esta pasta. "O Mike que está na sala" vira uma consulta, não uma aposta.
Dentro da memória de cada pessoa, o agente faz um julgamento para cada fato que registra: isso precisa estar na minha frente toda vez que eu falo com essa pessoa, ou só quando for relevante?
Pense em um bom colega de recepção que mantém um cartão de fichário por cliente frequente. Algumas coisas vão na frente do cartão porque importam em toda conversa — como alguém gosta de ser tratado, uma alergia grave. Todo o resto vai na gaveta: real, recuperável, mas não grudado na sua testa. Manter a frente do cartão curta é o ponto. Uma memória que traz tudo à tona é, na prática, uma memória que não traz nada útil — o único fato que importa se afoga nos cem que não importam.
O resto espera na gaveta até ser necessário. O que levanta o problema mais difícil: fazer o agente realmente abrir a gaveta.
Uma lição emprestada dos agentes de código
A falha clássica da memória baseada em arquivos é o agente decidir que a gaveta provavelmente é irrelevante e nunca olhar dentro dela. Então a pergunta virou: o que faz um assistente ir conferir de forma confiável?
A resposta veio de um lugar inesperado — os agentes de IA que escrevem software. Um agente de código não constrói um índice elaborado para achar uma função em uma base de código grande. Ele faz o que um engenheiro faz: busca nos arquivos diretamente, por texto puro, na hora. Rápido, exato, e o agente já sabe fazer isso. Tínhamos o mesmo formato — um conjunto de anotações em texto — então deixamos nossos agentes recuperarem da mesma forma: quando algo não está na frente do cartão, vá abrir os arquivos e procurar.
Vale deixar claro o que isso não é: não reconstruímos disfarçadamente o "buscar tudo" com um nome novo. Não há índice tentando adivinhar relevância. Há um lugar para cada pessoa e uma olhada direta quando uma pergunta específica surge — o mesmo movimento que um engenheiro faz para encontrar uma definição. Manter os fatos como anotações comuns, uma por pessoa, nos dá o quem e o ainda-verdadeiro quase de graça; buscar nelas diretamente nos dá recuperação sem um índice para manter sincronizado.
Funciona?
Testamos ao vivo, com um agente real em conversas reais, observando o que ele lembrava e como.
Ele se sustentou nas formas que mais importam. Fatos deixados "na gaveta" — uma alergia alimentar, o nome de um pet, um plano de viagem — foram lembrados corretamente quando perguntados, porque o agente foi lá olhar em vez de desistir. Dados alguns detalhes em uma única mensagem, o agente os arquivou de forma sensata por conta própria: colocou uma preferência de comunicação e uma alergia na frente do cartão, e guardou um detalhe de projeto com prazo na gaveta, exatamente onde cada um pertencia. E quando havia memória antiga, do tipo caderno único, sobrando por aí, o agente a reorganizou no novo formato por pessoa no meio do trabalho comum, sem ninguém pedir.
Estamos sendo deliberadamente cuidadosos com a palavra "funciona". Foram resultados animadores, não uma volta olímpica — um punhado de conversas com um modelo forte, não uma taxa de sucesso medida ao longo de milhares. O comportamento que mais nos deixa curiosos é se modelos menos capazes ainda abrem a gaveta de forma confiável, ou se eles recaem no "provavelmente irrelevante". E o sistema confia no julgamento do agente sobre o que vai na frente do cartão; colocamos um teto rígido em quanto pode ficar ali, mas um teto é uma rede de segurança, não bom gosto. Ensinar bom gosto é o trabalho em aberto.
O ponto maior
O que nos surpreendeu foi o quão pouco disso era sobre qualidade de recuperação. Não nos afastamos da busca porque a busca era ruim. Nos afastamos porque a unidade estava errada. Um caderno único não tem noção de quem; a busca por pura similaridade também não tem. Um espaço compartilhado faz de "quem, e ainda é verdade" a primeira pergunta, e a coisa mais barata que responde isso com honestidade é a mais humilde, aquela em que os agentes de código já confiavam: um conjunto de anotações comuns, um conjunto por pessoa, que você pode ler e buscar diretamente.
Isso nos deixa com perguntas melhores do que as que tínhamos no começo. Quão bem isso se sustenta quando um agente passa a conhecer centenas de pessoas? Dá para confiar que um agente cure a própria memória — que decida o que fica na frente do cartão e o que deixa esmaecer — ou isso sempre precisa da mão de um humano no botão? E até onde "projetar para o quem primeiro" viaja além das pessoas — para projetos, para times, para os outros agentes com quem um assistente divide uma sala?
Não achamos que a resposta seja mais memória. Achamos que é uma memória que sabe para quem ela é. Quando há mais de uma pessoa na sala, isso acaba sendo o jogo todo.