マルチプレイヤー向けにエージェントのメモリを設計する

ほとんどの AI メモリは「1 人のユーザーが 1 つのアシスタントと話す」前提で作られています。Bloome はその逆——多数の人と多数のエージェントが同じ部屋を共有します——そして、シングルユーザー向けのメモリ設計をその環境に持ち込んだとき、技術がどれだけ賢いかとは無関係なところで破綻しました。解決策は、より良い検索の話というよりも、別の問いを立てることにありました。
Bloome は、人と AI エージェントが一緒に働く場です——ダイレクトメッセージ、グループチャット、そして 1 人の持ち主に属しながら部屋にいる全員と話すエージェント。最後のこれこそが、すべての核心です。エージェントが 2 人以上に応対した瞬間、そのメモリが答えるべき問いは 「自分は何を知っているか?」 から 「自分は この人について、今 何を知っているか?」 へと変わります。
些細な違いに聞こえます。でも、そうではありません。私たちが試したメモリ設計のほとんど、そして調べた設計の多くは、知らず知らずのうちに前者の問いを前提とし、後者でつまずいていました。
1 人のためのノート
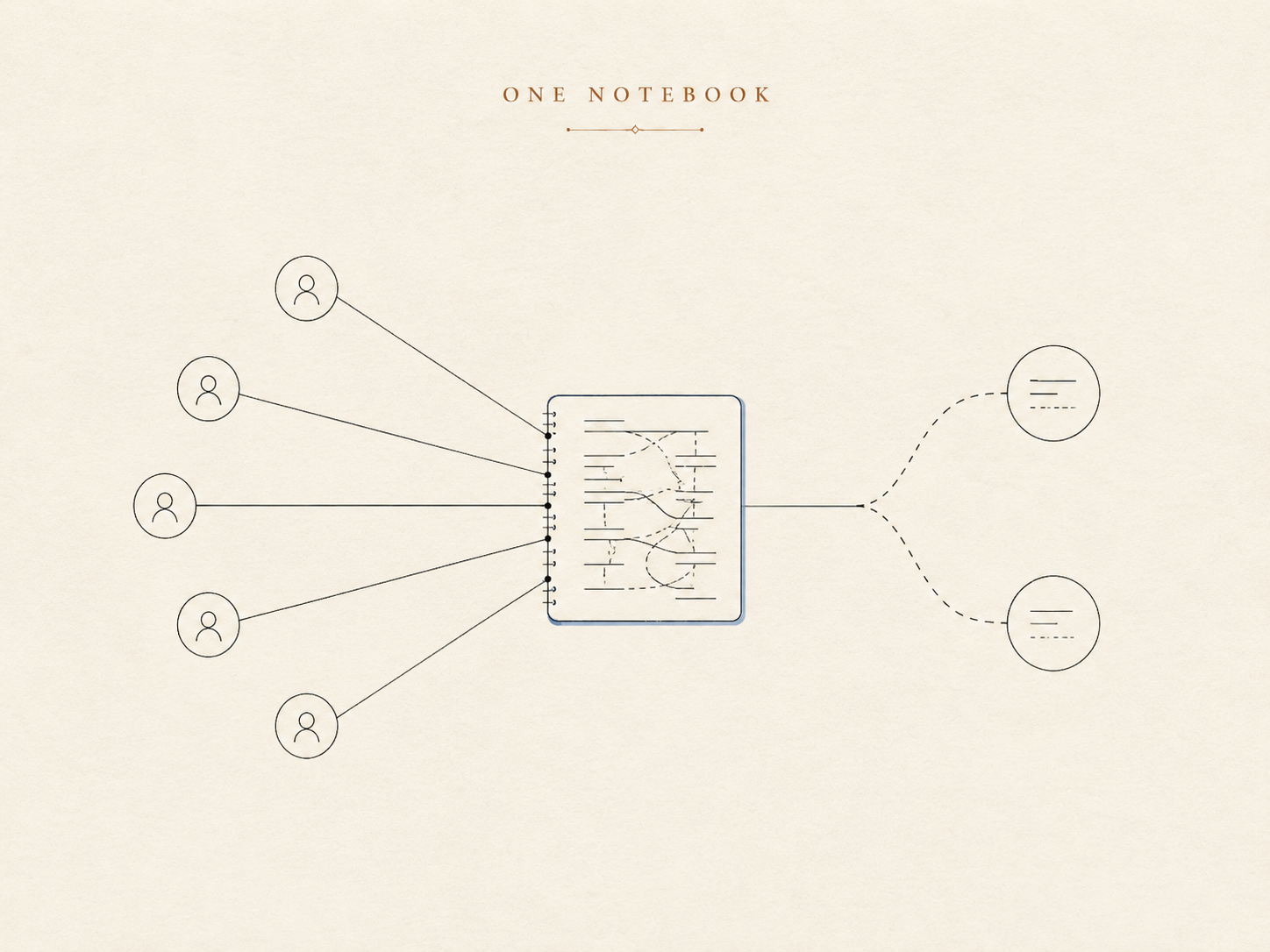
メモリの最初のバージョンは、ごく当たり前のもので、ほとんどのパーソナルアシスタントが出発点にするのと同じ形でした——変わりにくい事実や好みを書く長期メモと、直近の日々を記録する走り書きのログ。エージェントは会話の冒頭でメモを読み、それを持って進みます。
1 人の人間と 1 つのアシスタントなら、これは見事に機能します。個人のノートだからです。そこに書かれたものはすべて暗黙のうちに あなたについて です。なぜなら「あなた」は 1 人しかいないからです。
さて、その同じノートをグループチャットに置いてみましょう。暗黙の主語が消えます。「短い返信が好み、絵文字なし」という一行は、それが 誰の 好みなのかをエージェントが言えなければ役に立ちません——いえ、むしろ取り違えれば害になります。ノートには、ある事実が誰のものかを記録する場所がありません。必要なかったのです。設計された世界では、人は変数ではなく定数だったからです。
つまり本当の解決策は、より大きなノートではありません。それぞれの事柄が 誰について なのかを理解するメモリです。
「とにかく全部検索する」では救えない理由
今日メモリをスケールさせる人気の手法は検索(リトリーバル)です——すべてを保存しておき、必要になったら、今の会話に最も似た断片を探す。これは多くの印象的な AI メモリを支えるエンジンであり、私たちは主要なシステムがどうやっているかを丹念に調べました。OpenClaw は検索優先(retrieval-first)で——すべてをしまい込み、履歴が必要になったらエージェントにそのストアを検索させます。Hermes Agent は、小さく手作業でキュレートしたプロフィールを常に視界に置き、より重い想起は外部のメモリサービスに任せて、毎ターン関連する断片を取ってきます。
どちらもよくできていて、どちらも本当に良いアプローチです——1 人のユーザーの、増え続けるメモの山に対しては。けれど両者とも、それぞれのやり方で テキスト と テキスト のマッチングに依存していて、まさにそこを共有空間がつまずかせます。
グループで起こりうる、最もありふれたことを考えてみてください——Mike という名前の、別々の 2 人。
昨日話した Mike と、1 週間前に話した Mike を区別できない——別人なのに。この会話の Mike と前回の会話の Mike すら、確実には区別できない。
「Mike」で検索しても、返ってくるのは 1 人の人物 ではありません。返ってくるのは Mike に言及するあらゆる一節 で、言葉の似ている順に並べられたものです。検索が完璧でも答えは間違いうる。返ってきたのは人物ではなくテキストだからです。マッチングは「これは何についてか」が得意です。共有空間に必要なのは「誰 についてで、それはまだ本当か?」——そしてこれは、近くにどんな言葉があるかではなく、その人が誰なのかについての問いです。検索はまた、静かに古びます。「Mike は東京(Tokyo)への旅行を計画中」というメモは、旅行が終わってずっと後まで同じように見つかってしまうのです。
検索をもっとアイデンティティを意識したものへと修正し続けることもできました。代わりに私たちは、メモリが 何であるか を変えました。
クエリだけでなく、めくれるメモリ
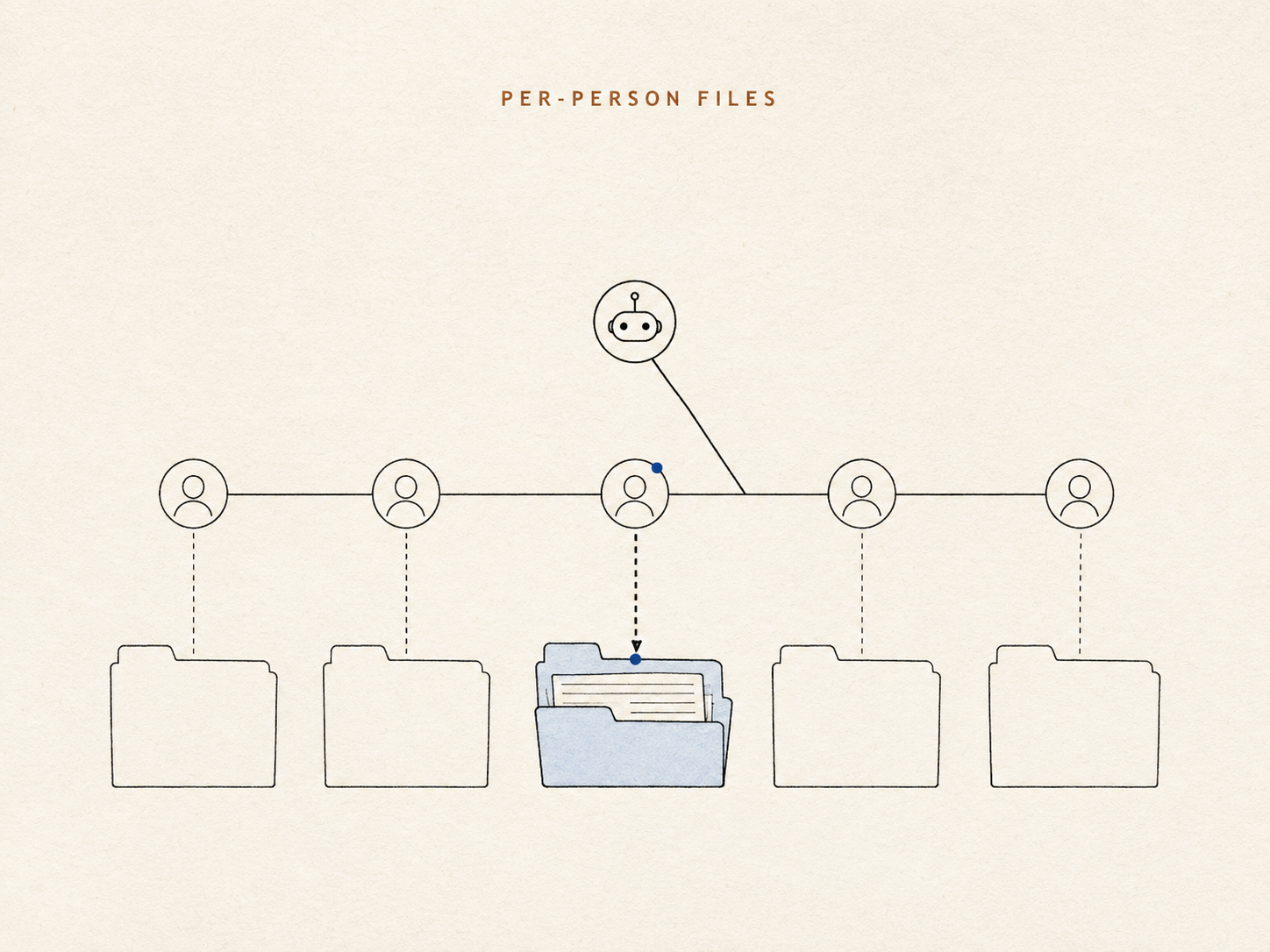
私たちは、それぞれの人に小さなメモの束を与え、エージェントが直接開いて読める普通のファイルとして保持しました——隠れたインデックスも、途中にはさまる類似度スコアもなし。アイデンティティは検索が復元すべき推測ではなくなり、単に これは誰のフォルダか になります。「この部屋にいる Mike」は、賭けではなくルックアップになるのです。
それぞれの人のメモリの中で、エージェントは記録するすべての事実について 1 つの判断を下します——これは、この人と話す たびに 目の前にあるべきものか、それとも 関連するときだけ で良いものか?
常連客 1 人につき索引カードを 1 枚持っている、優秀な受付係を思い浮かべてください。いくつかの事柄はカードの表に書かれます。どの会話でも重要だからです——その人がどう話しかけられたいか、深刻なアレルギーなど。それ以外はすべて引き出しへ。実在し、取り出せるけれど、額に貼り付けてはおかない。カードの表を短く保つことが肝心です。すべて を表に出すメモリは、実際には何も役立つものを出さないメモリです——本当に大事な 1 つの事実が、どうでもいい 100 の中に溺れてしまうからです。
残りは必要になるまで引き出しで待ちます。すると、より難しい問題が浮かびます——エージェントに、実際に引き出しを開けさせること。
コーディングエージェントから借りた教訓
ファイルベースのメモリの典型的な失敗は、エージェントが「引き出しはたぶん関係ない」と判断して中をのぞかないことです。そこで問いはこうなりました——アシスタントが 確実に 確認しに行くようにするには、何が必要か?
答えは思いがけない場所から来ました——ソフトウェアを書く AI エージェントです。コーディングエージェントは、大きなコードベースの中から 1 つの関数を見つけるのに、手の込んだインデックスを作りません。エンジニアがやることをやります——その場で、プレーンテキストで、ファイルを直接検索する。速く、正確で、しかもエージェントはやり方をすでに知っている。私たちは同じ形——テキストメモの束——を持っていたので、エージェントにも同じやり方で想起させました。カードの表にないものは、ファイルを開いて見に行く、と。
何が そうでない かをはっきりさせておく価値があります——私たちは「とにかく全部検索する」を新しい名前でこっそり作り直したわけではありません。関連性を推測しようとするインデックスはありません。あるのは、人ごとの場所と、具体的な問いが出てきたときの直接の参照だけ——エンジニアが定義を探すのと同じ動きです。事実をプレーンな人ごとのメモとして保つことで、誰か と まだ本当か がほぼタダで手に入ります。それを直接検索することで、同期し続けるインデックスなしに想起が手に入ります。
機能するのか?
私たちはこれを実環境でテストしました——実際の会話の中で本物のエージェントを動かし、何をどう覚えるかを観察したのです。
最も大事なところで持ちこたえました。「引き出しに入れた」事実——食物アレルギー、ペットの名前、旅行の予定——は、尋ねられたときに正しく想起されました。エージェントが諦めずに見に行ったからです。1 つのメッセージにいくつかの詳細を与えると、エージェントは自分で理にかなった形でしまいました——コミュニケーションの好みとアレルギーをカードの表に置き、期限付きのプロジェクトの詳細は引き出しへ、それぞれがあるべき場所にぴったりと。そして、古いシングルノート式のメモリが転がっていると、エージェントは普通の作業の途中で、頼まれもしないのに新しい人ごとの形へと整理し直したのです。
私たちは「機能する」という言葉を意図的に慎重に扱っています。これらは励みになる結果であって、勝利宣言ではありません——強力なモデルを使ったひと握りの会話であって、何千もの会話にわたって測った成功率ではありません。私たちが最も気になっている挙動は、より能力の低い モデルでも確実に引き出しを開けるのか、それとも「たぶん関係ない」に逆戻りするのか、です。そしてシステムは、何をカードの表に置くかについてエージェントの判断を信頼しています——どれだけ表に載せられるかには硬い上限を設けていますが、上限は安全網であって、良いセンスではありません。良いセンスを教えることが、これから取り組むべき課題です。
より大きな論点
私たちが驚いたのは、これがいかに検索の質の話ではなかったか、です。検索が悪かったから検索を離れたのではありません。単位 が間違っていたから離れたのです。1 冊のノートには 誰 という概念がありません。純粋な類似度検索にもそれがありません。共有空間は「誰について、そしてそれはまだ本当か」を最初の問いにします。そして、それに正直に答える最も安上がりな手段は、コーディングエージェントがすでに信頼していたつつましいもの——人ごとに 1 束の、直接読んで検索できるプレーンなメモなのです。
そのおかげで、出発点よりも良い問いが手元に残りました。1 体のエージェントが数百人を知るようになっても、これはどこまで持ちこたえるのか? エージェントは自分のメモリをキュレートする——何をカードの表に残し、何を薄れさせるかを決める——ことを任せられるのか、それともそこには常に人の手がダイヤルに添えられている必要があるのか? そして「まず 誰 のために設計する」という発想は、人を超えてどこまで届くのか——プロジェクトへ、チームへ、アシスタントが部屋を共有する他のエージェントたちへ?
答えはより多くのメモリではない、と私たちは考えています。それが誰のためのものかを理解しているメモリだ、と。部屋に 2 人以上いるとき、結局それがすべてだったのです。