为多人多 agent 场景设计 agent 记忆

几乎所有 AI 记忆系统都是为「一个人对一个助手」设计的。Bloome 恰好相反 —— 很多人和很多 agent 共享同一批房间 —— 当我们把单用户的记忆设计放进这种场景时,它崩掉的方式,跟技术本身有多聪明毫无关系。最后真正解决问题的,与其说是更好的搜索,不如说是换了一个要回答的问题。
Bloome 是一个让人和 AI agent 一起协作的地方 —— 私聊、群聊,以及那种归属于某一个人、却要跟房间里所有人说话的 agent。整个故事的关键就在最后那一点。一旦某个 agent 要服务的不止一个人,它的记忆要回答的问题,就从「我知道什么?」变成了「关于这个人、此时此刻,我知道什么?」。
听起来差别很小,其实不然。我们试过的几乎每一种记忆设计,以及我们研究过的大多数方案,都在悄悄地默认了前一个问题,然后在后一个问题上栽了跟头。
一本只给一个人用的笔记本
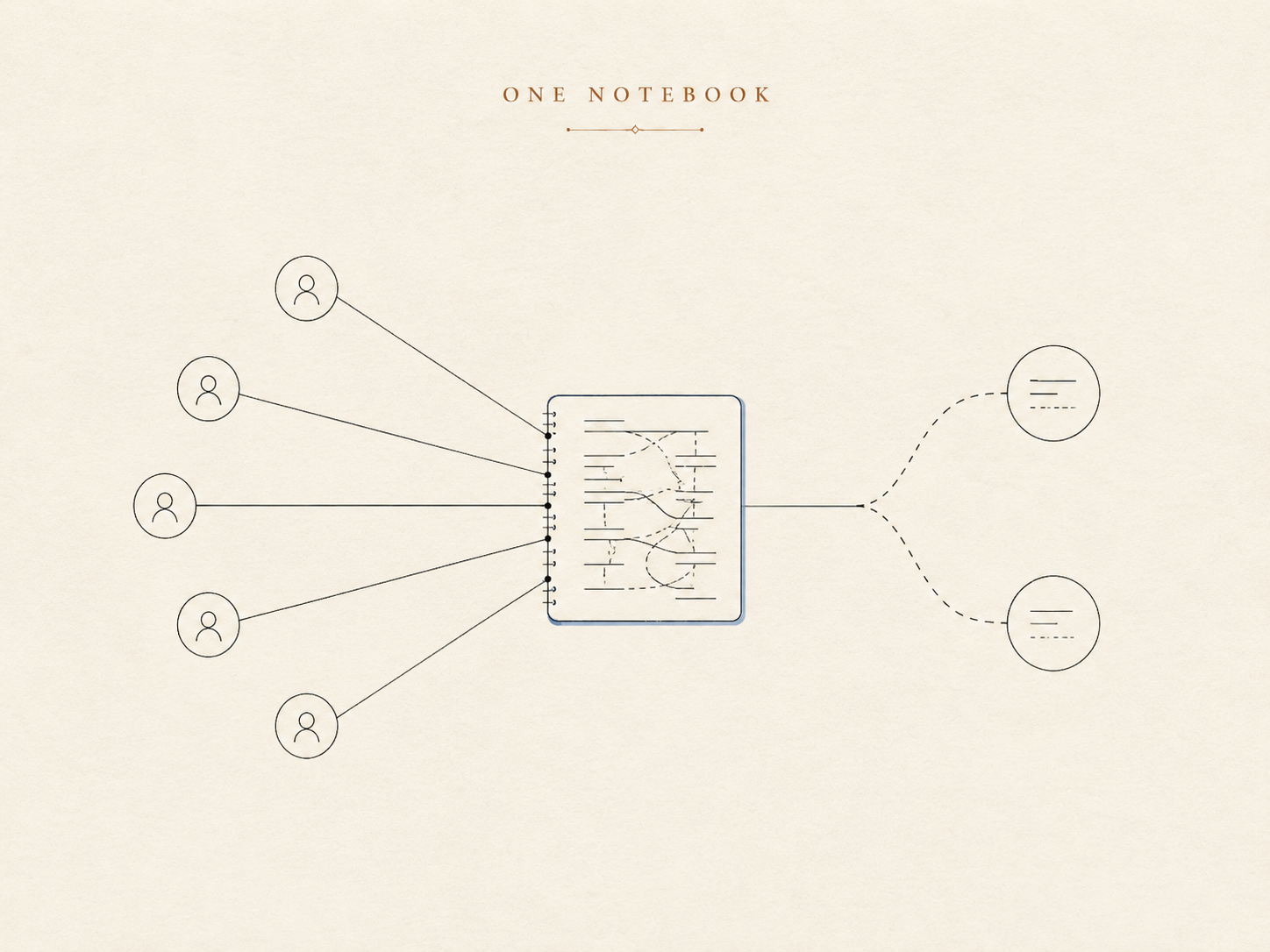
记忆的第一个版本是最显而易见的那种,跟大多数个人助手起步时的形态一样:一份记录耐久事实和偏好的长期笔记,外加一份记录最近几天的滚动日志。agent 在对话开始时读一遍长期笔记,然后一路带着它。
对一个人和一个助手来说,这套机制运转得很漂亮。它就是一本私人笔记本。写进去的每一条都隐含着「关于你」,因为「你」只有一个。
现在把同一本笔记本放进群聊。那个隐含的主语消失了。一句「偏好简短回复,不要 emoji」变得毫无用处 —— 甚至更糟,会被张冠李戴 —— 如果 agent 说不清这是_谁_的偏好。这本笔记本没有地方记录某条事实属于谁。它从来不需要这样的地方,因为在它被设计的那个世界里,「人」是一个常量,而不是一个变量。
所以真正的解法不是一本更大的笔记本。而是一种知道每件事「关于谁」的记忆。
为什么「全都搜一遍」救不了它
如今扩展记忆最流行的做法是检索:把一切都存下来,需要时再搜出和当前对话最相似的那几段。它是很多令人印象深刻的 AI 记忆背后的引擎,我们也仔细研究过领先系统是怎么做的。OpenClaw 走的是检索优先 —— 把一切都归档,需要历史时让 agent 去那个存储里搜。Hermes Agent 则是始终把一份小而精、人工策划的档案摆在眼前,把更重的回忆工作交给一个外部记忆服务,每一轮按需取出相关片段。
两种都做得不错,也都是真正优秀的方案 —— 对一个人不断堆积的笔记而言。但它们各自都以某种方式依赖把_文本_匹配_文本_,而这恰恰是共享空间会把它们绊倒的地方。
想想群里最稀松平常的一件事:两个都叫 Mike 的不同的人。
我分不清昨天跟我聊过的那个 Mike 和一周前跟我聊过的那个 Mike —— 他们是不同的人。我甚至没法可靠地分清这次对话里的 Mike 和上次对话里的 Mike。
搜「Mike」,你拿回来的不是_一个人_;你拿回来的是_每一段提到某个 Mike 的文字_,按词面相似度排序。搜索可以做得完美无缺,答案却照样是错的,因为返回的是文本,不是人。匹配擅长回答「这是关于什么的」。共享空间需要的是「这是关于_谁_的,而且它现在还成立吗?」 —— 这是一个关于「某人是谁」的问题,而不是关于「哪些词挨得近」的问题。检索还会悄悄过期:一条写着「Mike 在计划去 Tokyo 旅行」的笔记,在旅行早已结束之后,依然一样好搜。
我们本可以继续打补丁,让搜索更懂身份。但我们没有,我们改变了记忆「是什么」。
能翻阅的记忆,而不只是能查询的记忆
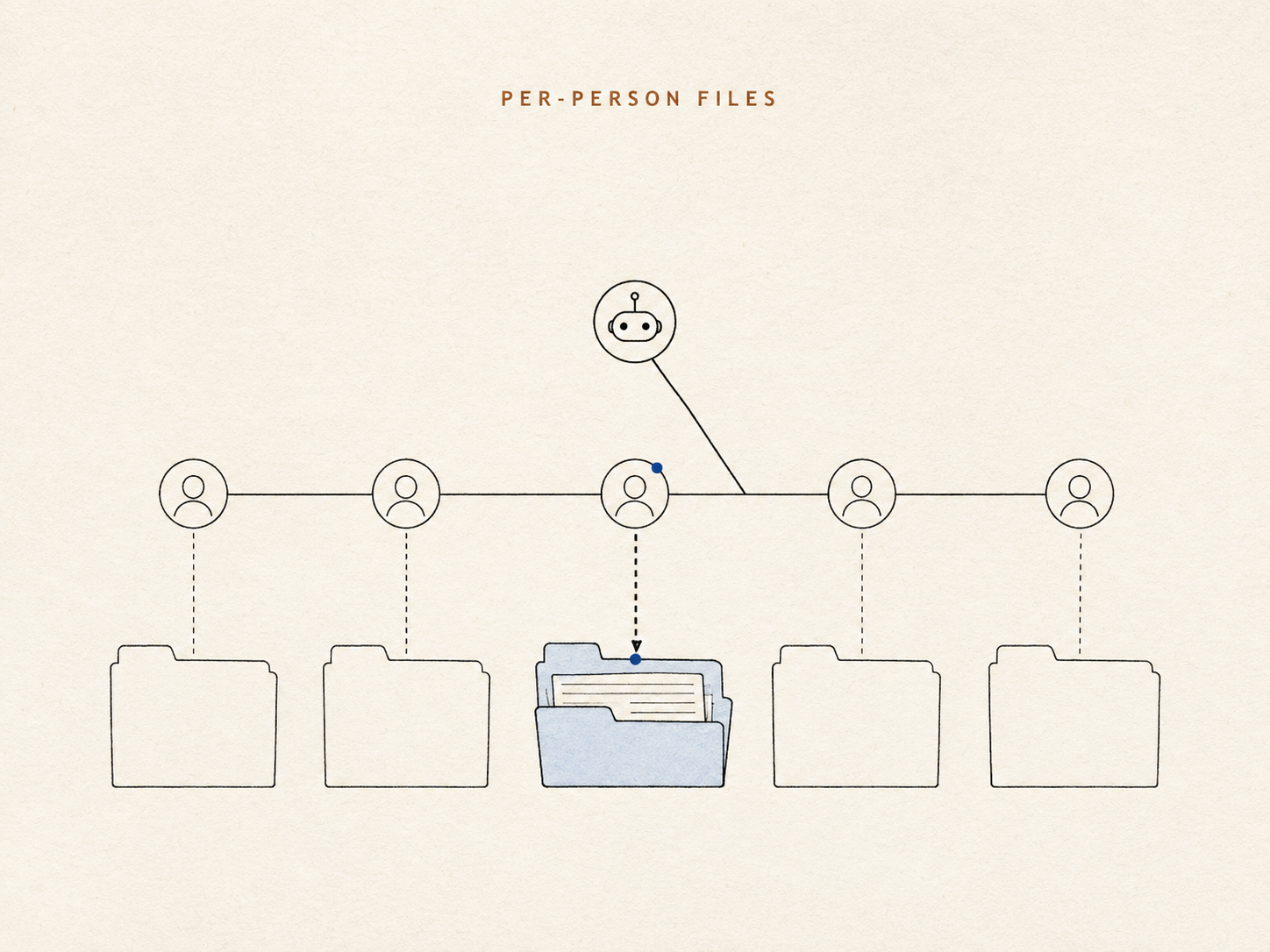
我们给每个人一小套属于他们自己的笔记,以普通文件的形式保存,agent 可以直接打开来读 —— 没有隐藏的索引,中间也没有相似度分数。身份不再是搜索得费劲还原的一次猜测;它就是「这是谁的文件夹」而已。「房间里那个 Mike」从一场赌博变成了一次查表。
在每个人的记忆内部,agent 对它记录的每一条事实都做一个判断:这条该不该_每次_我跟这个人说话时都摆在我面前,还是只有_相关时_才出现?
想象一位称职的前台同事,他给每位常客都保留一张索引卡。有几件事写在卡片正面,因为它们在每次对话里都重要 —— 某人喜欢怎样被称呼、一项严重的过敏。其余的都放进抽屉:真实、可取回,但不会贴在你脑门上。让卡片正面保持简短,正是关键所在。一份把_所有东西_都端上来的记忆,实际上就是一份端不出任何有用东西的记忆 —— 那一条要紧的事实,会淹没在一百条不要紧的里面。
其余的就在抽屉里等着,直到被需要。这又引出了更棘手的问题:怎么让 agent 真的去把抽屉打开。
一个借鉴自编码 agent 的教训
基于文件的记忆有一个经典的失败模式:agent 认定那个抽屉八成无关,就压根不往里看。于是问题变成了:什么能让一个助手_可靠地_去查一下?
答案来自一个意想不到的地方 —— 那些写软件的 AI agent。一个编码 agent 不会为了在一个大代码库里找一个函数而建一套精巧的索引。它做的是工程师会做的事:当场直接按纯文本去搜文件。快、准,而且 agent 本来就会。我们手上是同样的形态 —— 一组文本笔记 —— 于是我们让自己的 agent 用同样的方式回忆:当某件事不在卡片正面时,就去打开文件翻一翻。
有必要说清楚这_不是_什么:我们没有偷偷把「全都搜一遍」换个名字重建一遍。这里没有一套试图猜测相关性的索引。这里有的是给每个人留的一处位置,以及当具体问题出现时的一次直接翻看 —— 跟工程师去找一个定义时做的动作一模一样。把事实保存为朴素的、按人分的笔记,几乎不费力就给了我们「关于谁」和「现在是否_仍然成立_」;直接去搜它们,则让我们拿到了回忆能力,而不必维护一套需要保持同步的索引。
它管用吗?
我们做了实测,用一个真实的 agent 放进真实的对话里,观察它记住了什么、怎么记的。
它在最要紧的几个方面顶住了。那些「留在抽屉里」的事实 —— 一项食物过敏、一只宠物的名字、一个旅行计划 —— 被问到时都被正确回忆了起来,因为 agent 去翻了,而不是直接放弃。在单条消息里给出几个细节后,agent 自己就把它们归得很合理:它把一项沟通偏好和一项过敏放上了卡片正面,把一个有时效的项目细节塞进了抽屉,各就各位。而当周围还散落着旧的、单笔记本式的记忆时,agent 在日常工作中途、没人要求的情况下,主动把它们重组成了新的按人分的形态。
我们对「管用」这个词是刻意谨慎的。这些是令人鼓舞的结果,而不是一场胜利的庆功 —— 是用一个强模型做的少数几场对话,而不是跨越成千上万次、测算出来的成功率。我们最好奇的行为是:_能力较弱_的模型是否还会可靠地去打开抽屉,还是会退回到「八成无关」。而且这套系统信任 agent 自己对「什么该放上卡片正面」的判断;我们给「正面能放多少」设了一个硬上限,但上限是一道兜底,不是好品味。教会它好品味,是尚未做完的工作。
更大的那个点
让我们意外的是,这件事跟检索质量的关系竟然这么小。我们离开搜索,不是因为搜索不好。我们离开,是因为_单位_错了。一本笔记本没有「谁」的概念;纯相似度搜索同样没有。共享空间让「关于谁,而且它现在还成立吗」成了第一个问题,而最廉价、又能诚实回答它的,恰恰是编码 agent 早已信赖的那个朴素东西:一组朴素的笔记,一人一套,可以直接读、直接搜。
这给我们留下了比起步时更好的一批问题。当一个 agent 逐渐认识成百上千个人时,这套机制还能撑多好?一个 agent 能不能被信任去策划自己的记忆 —— 自己决定什么留在卡片正面、什么任其淡去 —— 还是说这件事永远需要一只人手按在旋钮上?以及,「先为_谁_而设计」这个思路,能从「人」往外走多远 —— 走到项目、走到团队、走到一个助手在房间里共处的其他 agent 身上?
我们不认为答案是更多的记忆。我们认为答案是一种知道「它记给谁」的记忆。当房间里不止一个人时,这一点最终成了整个游戏的关键。