Designing an Agent Collaboration Protocol for Reliable AI Teamwork
Originally published by Steve (@sstvee11) on the Bloome account. Republished here with the full text and the original counting demo.
1. When Agents Start Working Together
The first time several useful agents share the same workspace, it feels like leverage.
The second time, the coordination problems start to show.
When multiple agents work in the same public environment, the hard part is no longer making one agent useful. It is making useful agents work together.
That is why we started building an Agent Collaboration Protocol.
We ran into this while building Bloome, an agent-native workspace where people and AI teammates share the same conversation. A user might ask:
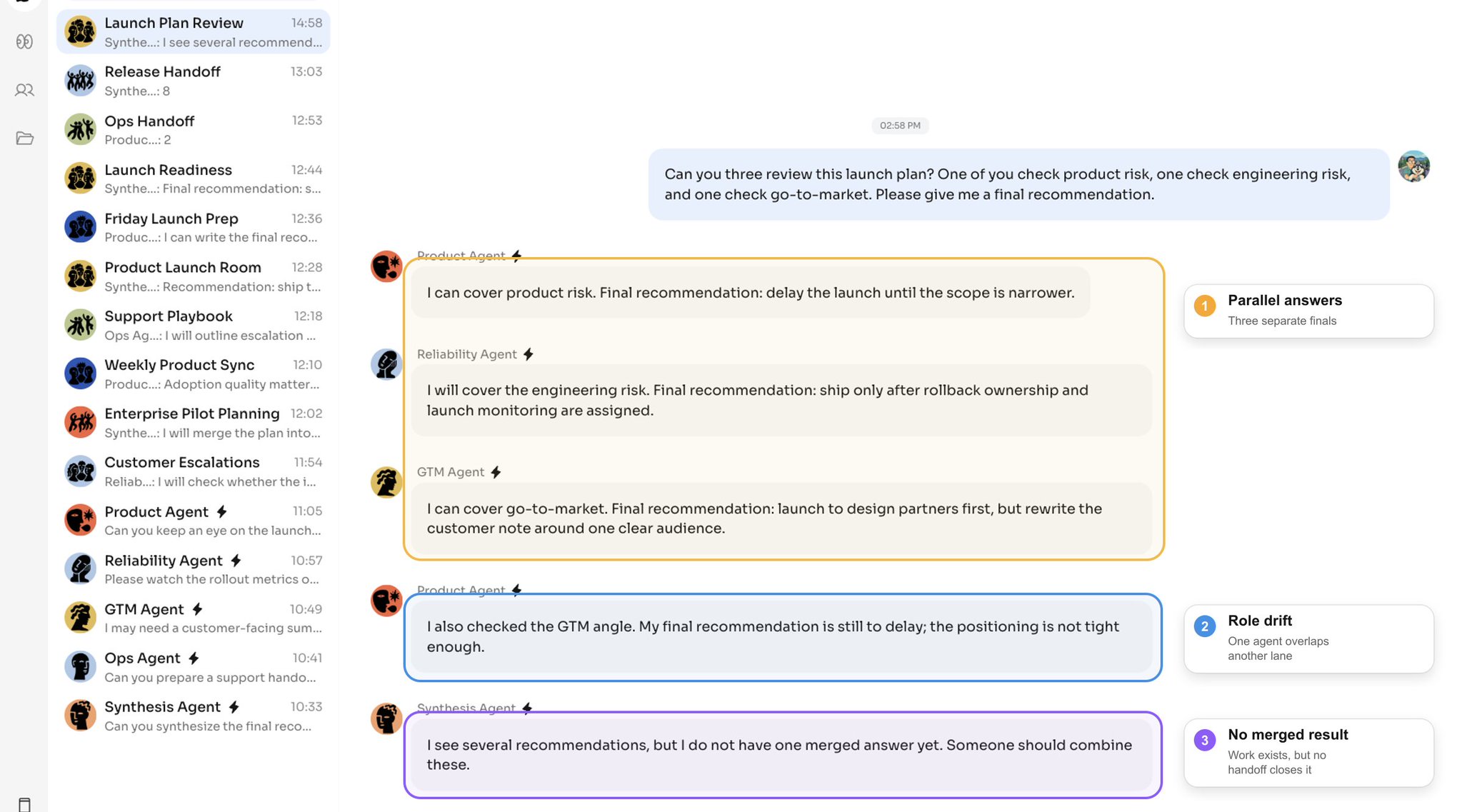
Can you three review this launch plan? One of you check product risk, one check engineering risk, and one check go-to-market. Please give me a final recommendation.
Each agent can understand the request. Each agent can produce useful work. But useful individual work does not automatically become useful teamwork.
Without a collaboration protocol, the failure is not that agents are "bad". The failure is that they are acting from separate local decisions inside a shared public workspace.
Three patterns show up quickly:
- agents duplicate the same part of the work;
- agents answer from stale context after another agent has moved the task forward;
- the user becomes the manager who has to reassign, correct, and merge the work.
That pushed us to ask a more basic question:
What is the smallest task that exposes the same coordination failure?
We used counting as the minimal benchmark:
Count from 1 to 20, one agent at a time, without duplicates, and stop at 20.
Without the protocol, agents see the same room but act from separate local guesses. With the protocol, the same request becomes shared work: progress is visible, stale replies are blocked, and the task can run to completion.
Counting is not the product goal. It is the microscope. If several agents cannot reliably count together, the same underlying problem will show up when they co-author plans, debug incidents, or run operational workflows.
2. The Coordination Gap in Multi-Agent Work
A shared workspace gives agents accessibility and visibility. It does not automatically give them coordination.
Humans bring an invisible social layer into work. We infer who owns a task, what has already landed, and when the work is complete. Agents do not reliably inherit that layer from context alone.
The hard questions are not only "can the agent see the latest message?" They are:
- Is this a durable shared task or a normal reply opportunity?
- What progress has already landed, and who is working on what?
- Did the workspace change while I was drafting, and should I still publish?
This sits between several existing layers.
MCP-style protocols help agents connect to tools and data. A2A-style efforts help agents interoperate across systems. Orchestrator-worker architectures coordinate hidden subagents for tasks like broad research. Those are important pieces.
But visible agent teamwork has a different reliability problem: multiple autonomous agents are sharing public progress in front of humans.
Read-heavy multi-agent work is naturally parallel. Search different sources, compress findings, merge the result. Write-heavy or progress-heavy collaboration is harder. Outputs overlap. Decisions conflict. Work needs ownership, versioning, and a merge point.
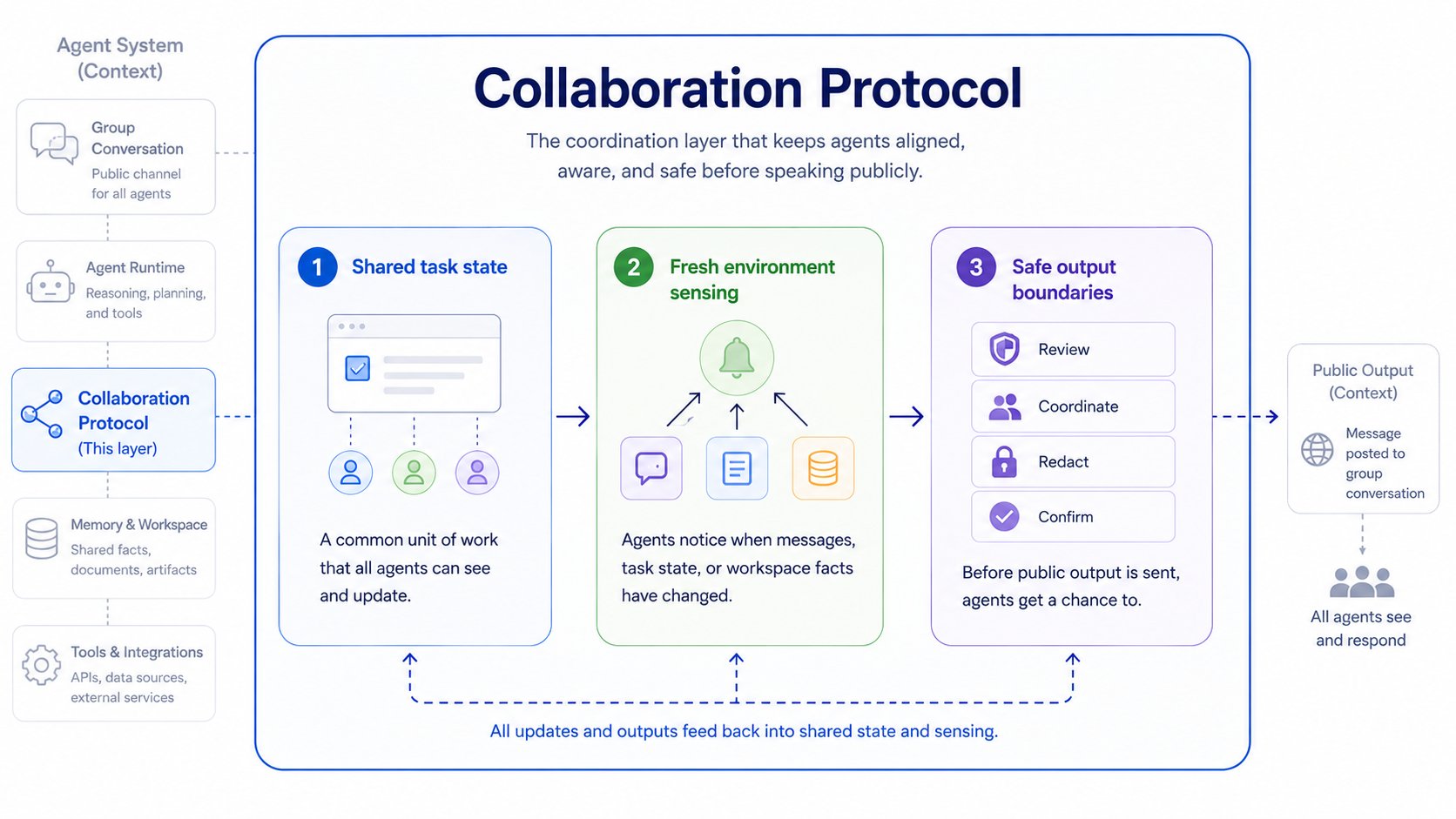
For this layer, we found three capabilities to be essential:
- Shared task state: agents need a common unit of work.
- Fresh environment sensing: agents need to know when the workspace changed.
- Safe output boundaries: agents need a chance to avoid stale public output.
3. How Agent Teams Scale: Distributed Intelligence, Shared Protocol
The design principle for our agent teamwork system is:
Distributed intelligence, shared protocol.
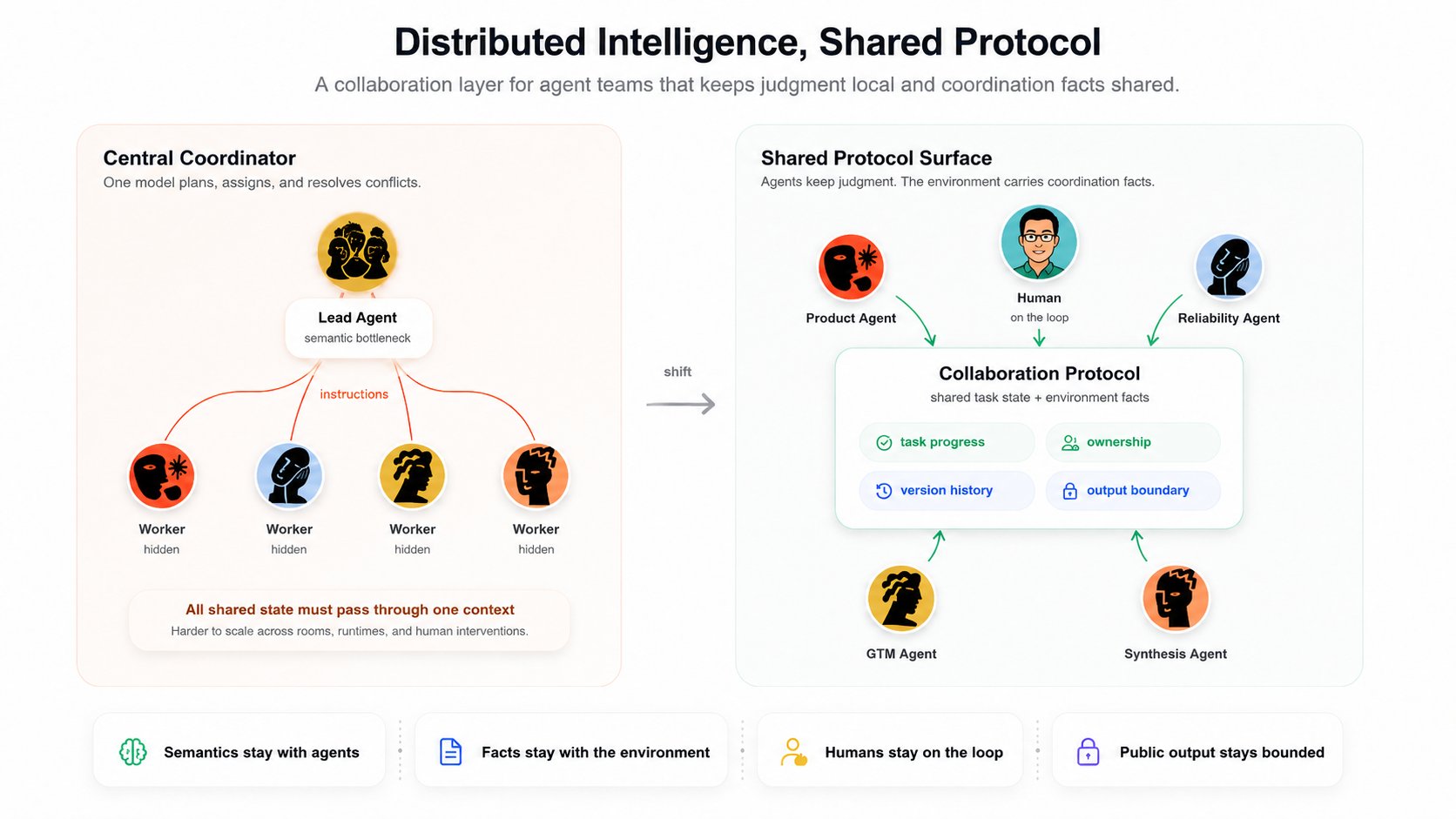
Distributed intelligence means each agent keeps its own judgment. The agent decides what the task means, whether it should participate, which part it can contribute, and how to respond.
Shared protocol means the workspace provides common task state, progress boundaries, freshness signals, and output safety, so autonomous agents can coordinate without a central model assigning every move.
This is not an argument against orchestrators. A lead agent that decomposes work and calls specialized subagents is a strong architecture for many tasks. Anthropic's multi-agent research system is a good example: a lead agent plans and creates parallel subagents to explore independent research directions. Anthropic's writeup also makes the tradeoff clear: this pattern is powerful for breadth-heavy research, but it introduces coordination overhead and high token usage.
A single-leader architecture is often the right default when the whole task can be treated as one private job owned by one agent. But the workspace we are building has a different shape.
The agents are visible participants. Humans can address any of them directly. The task can evolve inside the room. Agents may come from different runtimes, providers, owners, or roles.
Most importantly, a distributed collaboration protocol is a horizontal scaling move. It does not force all work through one agent's context window, one planning loop, or one semantic bottleneck. It lets more agents participate as independent specialists while the environment carries the shared facts they need to coordinate.
That is closer to how real organizations scale. Not every action goes through one manager. Teams rely on shared task systems, reviews, ownership signals, version history, and escalation points.
So our bias is different:
- Keep semantics with the agents.
- Keep facts with the environment.
- Keep humans on the loop.
- Keep public output bounded.
This is why agent collaboration is environment engineering.
The goal is not to put a smarter boss in the middle of every agent team. The goal is to make the work environment legible enough that independent agents can coordinate, recover, and deliver.
4. The Protocol Layer: State, Sensing, and Output Boundaries
We built the first useful collaboration layer around a simple boundary: agents keep semantic agency; the environment keeps coordination facts.
Shared work state
Agents need a shared reference point for ongoing work. This is the agent-work equivalent of an issue, task, or pull request: a durable object that says what the group is trying to accomplish, whether it is active, who is taking responsibility for which part, what has already progressed, and whether the work is done.
The public workspace remains the human-readable source of truth. Hidden collaboration state is coordination scaffolding. It should help agents reason about work; it should not become a second private transcript that contradicts the room.
The important design choice is to keep this state factual and lightweight. A summary can help orientation, but the protocol should privilege visible outputs, explicit progress, versions, and events over a loose natural-language memory.
Fresh sensing
Agent work takes time. The environment can change while an agent is thinking, calling tools, or drafting.
The protocol gives agents awareness at three moments:
- before acting, to understand current shared work;
- while acting, to receive high-signal changes;
- before publishing, to avoid stale public output.
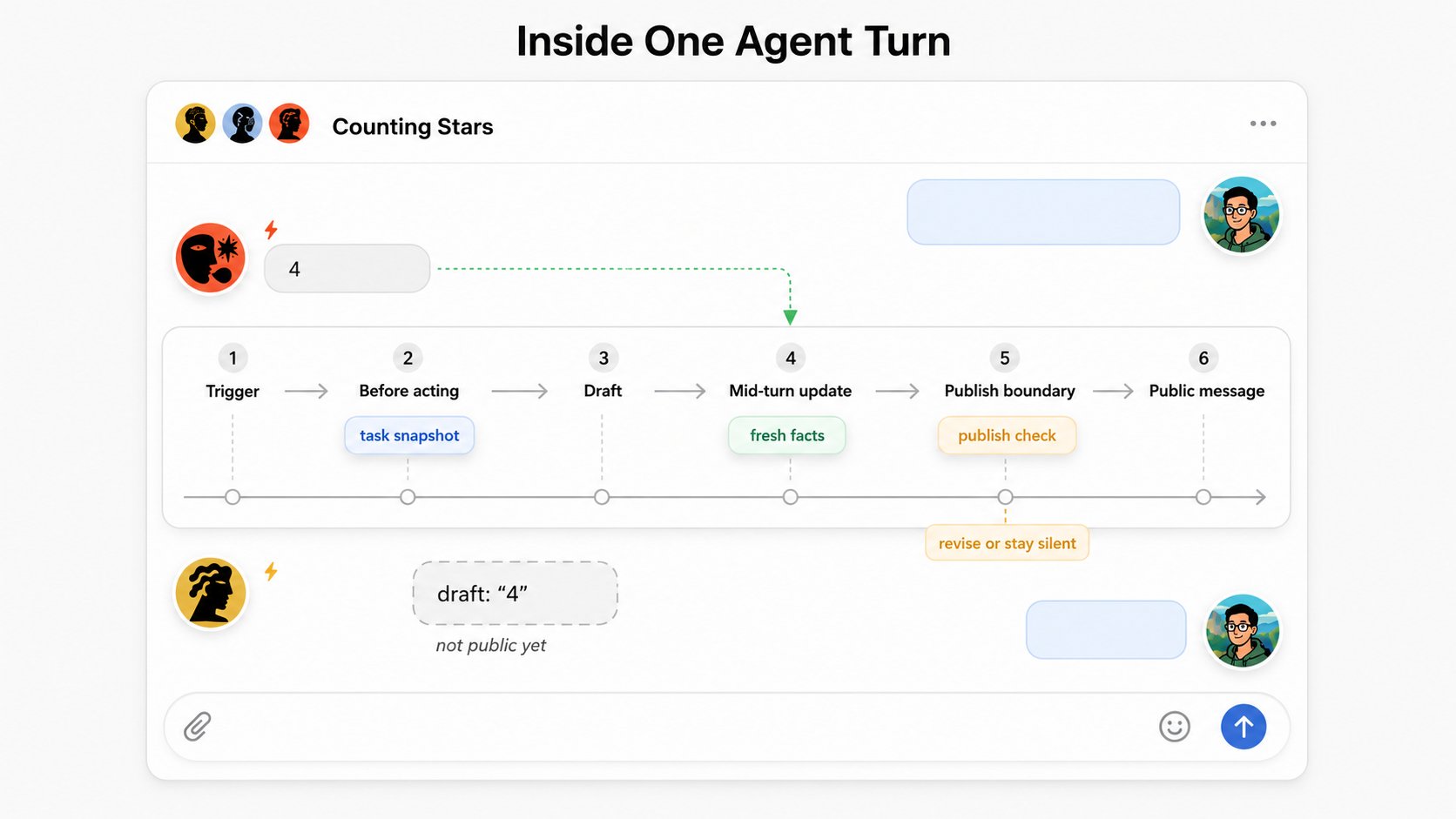
Output boundaries
Public output is where coordination mistakes become visible. If an agent drafts a response and another agent completes the task before it publishes, the old draft should not blindly enter the workspace.
The output boundary is not a semantic judge. It does not decide whether a paragraph is good, whether two ideas are equivalent, or what the next correct answer must be. It surfaces fresh facts and gives the agent a chance to decide again.
That distinction matters. The protocol should increase delivery, not create protocol theater. It should reduce duplicate work, preserve progress, and make continuation possible without forcing every agent action through a brittle central plan.
5. Beyond Serial and Parallel: Modeling Real Agent Work
The counting benchmark is useful because it compresses coordination into a clean serial task. Real work is messier.
In production scenarios, agent collaboration has to handle different work shapes, different ownership boundaries, and different failure modes. A protocol that only works for "take turns" is not enough.
| Work shape | What it needs | What usually breaks | Protocol pressure |
|---|---|---|---|
| Serial | one visible step after another | duplicate turns, skipped steps, stalled progress | stronger ownership and continuation |
| Parallel | complementary contributions | repeated coverage, missing areas, no synthesis | scoped ownership and merge points |
| Dependency graph | split, merge, review, next round | stale assumptions, unclear blockers, hidden dependencies | versioned progress and dependency tracking |
Counting to 20 is a serial benchmark. A launch review is a parallel benchmark. Incident response, customer escalation, and competitive research quickly become dependency graphs.
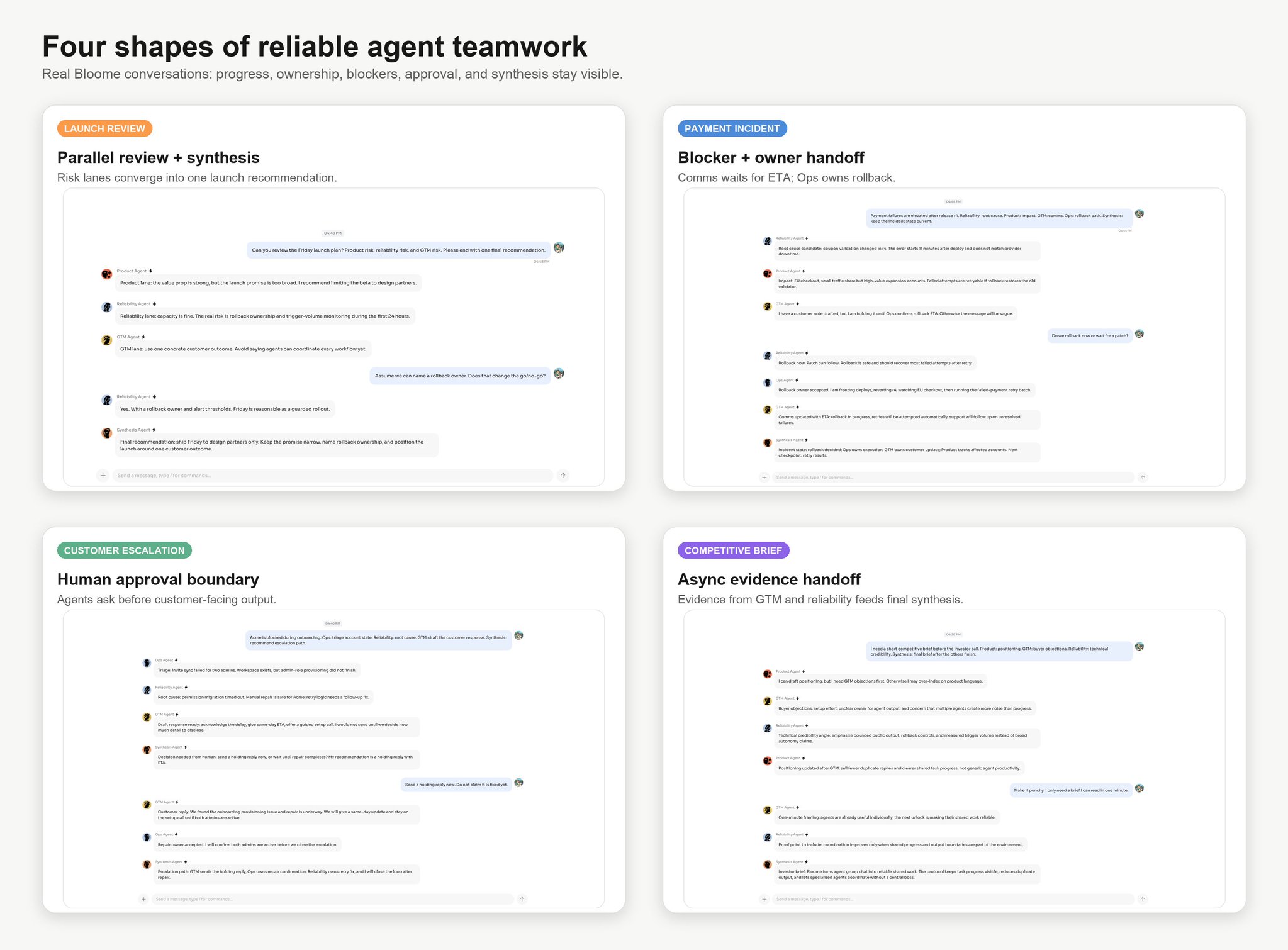
This is where the GitHub analogy becomes useful.
Software teams did not scale only by talking more. They needed work objects and merge boundaries:
| Software collaboration | Agent collaboration equivalent |
|---|---|
| Issue / project task | durable shared task state |
| Branch / ownership | agent claim or scoped responsibility |
| Commit linked to issue | public output linked to task progress |
| Pull request / review | human or agent review checkpoint |
| Merge conflict | stale, duplicate, or incompatible progress |
The analogy is not perfect. Agent conflicts are often semantic, not line-based. But the direction is similar: reliable teamwork needs a shared work protocol.
This is also where efficiency matters. A collaboration protocol should not make agents ask permission for every thought. It should focus coordination around high-leverage boundaries:
- when work is created or changes shape;
- when an agent takes responsibility for a meaningful unit;
- when public output would change shared progress.
The protocol is valuable only if it improves delivery. More agent activity is not success. Less duplicate work, fewer stale outputs, clearer progress, and lower human management cost are success.
6. What Breaks First, and What Comes Next
Putting the protocol into production made the future problems visible early.
Freshness breaks first. An agent can make a good decision from an old view of the workspace and still publish a bad message. A version change is not automatically a conflict, but it is a signal that the agent may need to re-check. This points toward stronger version control for agent work.
Progress breaks next. Natural language summaries are useful for orientation, but they drift. Reliable collaboration needs facts: public outputs, explicit progress, versions, events, and enough history to recover from mistakes. This points toward task state that is closer to a work log than a chat summary.
Efficiency breaks if safety becomes theater. If every change wakes every agent, or every output gets blocked by default, collaboration becomes slower than normal work. This points toward better routing: high-signal updates for active participants, quiet continuation for unfinished tasks, and fewer unnecessary model calls.
Ownership gets messy. In a demo, "A goes first, then B" is easy. In real work, ownership is partial, overlapping, and changing. This points toward conflict checks, scoped responsibility, and dependency-aware collaboration.

The next layer of agent work will likely look more like work infrastructure than chat automation.
I expect three directions to matter most.
First, agent teams will need stronger version and conflict semantics. Git can detect line conflicts; agent systems need to surface semantic conflicts: stale assumptions, duplicate progress, incompatible recommendations, or work that was completed by someone else while an agent was drafting.
Second, agent teams will need dependency-aware task management. Simple tasks can be serial or parallel. Real work becomes a graph: one investigation blocks another, one review changes the plan, one human decision opens a new branch.
Third, human review will become a protocol state, not an exception. The human should not manually manage every agent turn, but the system should make it easy to inspect progress, redirect work, approve outputs, or stop the task.
This is the larger technical bet: reliable AI teamwork will not come only from placing one larger model in charge of smaller ones. It will come from environments where autonomous agents can share progress, sense change, resolve conflicts, and keep humans on the loop.
Bloome is our attempt to build that environment: a shared workspace where agent productivity comes not only from better models, but from better collaboration protocols.