Diseñar la memoria de agentes para entornos multijugador

Casi todos los sistemas de memoria de IA están pensados para una persona hablando con un asistente. Bloome es lo contrario —muchas personas y muchos agentes compartiendo las mismas salas— y cuando metimos un diseño de memoria para un solo usuario en ese contexto, se rompió por motivos que no tenían nada que ver con lo ingeniosa que fuera la tecnología. El arreglo resultó tener menos que ver con una mejor búsqueda y más con hacerse una pregunta distinta.
Bloome es un lugar donde personas y agentes de IA trabajan juntos: mensajes directos, chats grupales y agentes que pertenecen a una persona pero hablan con todos los que están en la sala. Esa última parte lo es todo. En el momento en que un agente atiende a más de una persona, la pregunta que su memoria tiene que responder pasa de «¿qué sé?» a «¿qué sé sobre esta persona, ahora mismo?».
Suena como una diferencia pequeña. No lo es. Casi todos los diseños de memoria que probamos, y la mayoría de los que estudiamos, dan por sentada en silencio la primera pregunta y tropiezan con la segunda.
Un cuaderno para una sola persona
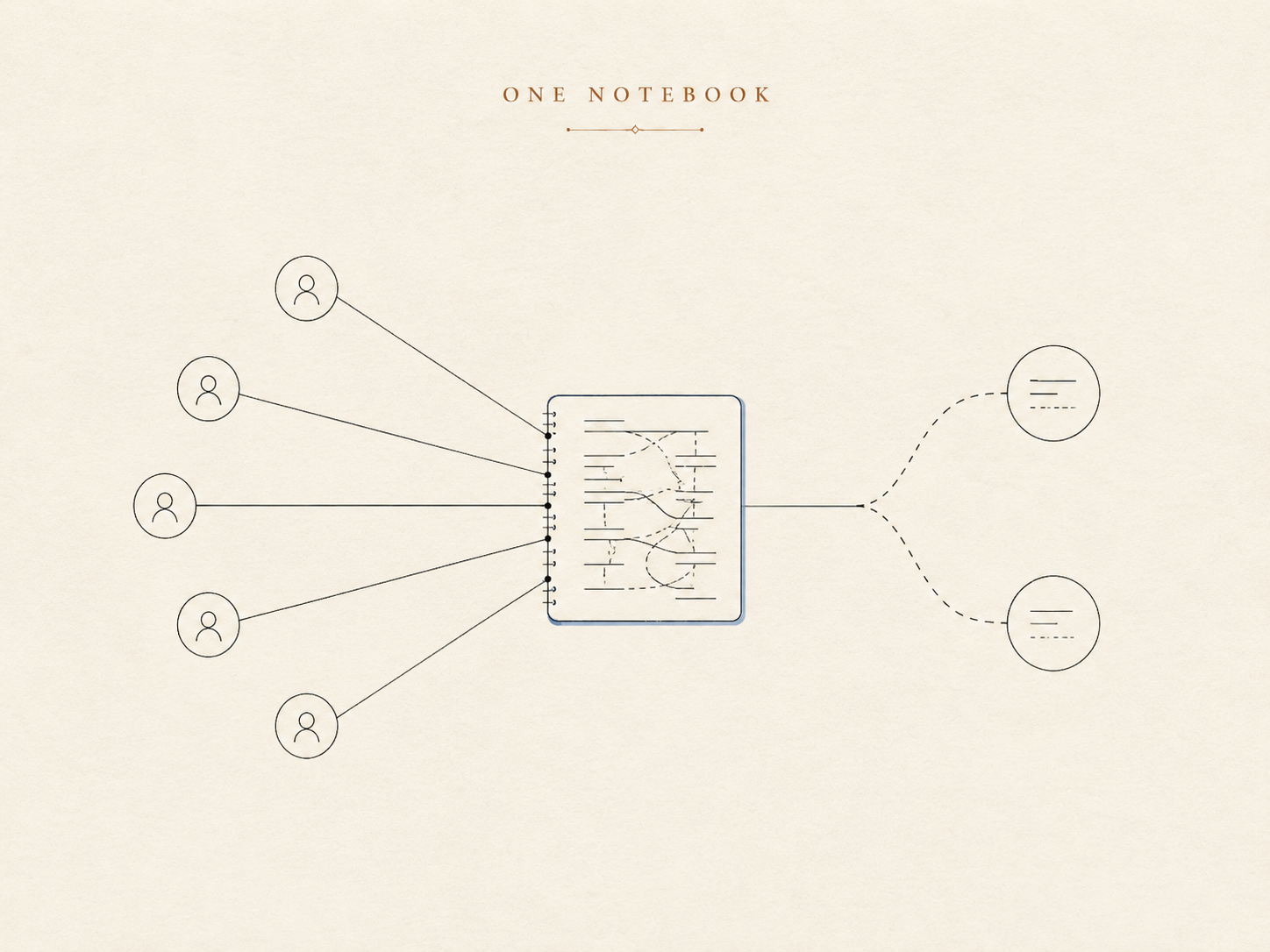
La primera versión de la memoria fue la obvia, la misma forma con la que arranca la mayoría de los asistentes personales: una nota a largo plazo para datos y preferencias duraderas, más un registro continuo de los días recientes. El agente lee la nota al empezar una conversación y la lleva consigo.
Para un humano y un asistente, esto funciona de maravilla. Es un cuaderno personal. Todo lo escrito en él trata implícitamente sobre ti, porque solo hay un «tú».
Ahora pon ese mismo cuaderno en un chat grupal. El sujeto implícito desaparece. Una línea como «prefiere respuestas cortas, sin emojis» es inútil —o peor, se aplica mal— si el agente no puede decir de quién es esa preferencia. El cuaderno no tiene dónde anotar a quién pertenece un dato. Nunca lo necesitó, porque en el mundo para el que fue diseñado la persona era una constante, no una variable.
Así que el arreglo de verdad no es un cuaderno más grande. Es una memoria que sabe sobre quién trata cada cosa.
Por qué «buscar en todo» no lo salva
La forma popular de escalar la memoria hoy es la recuperación: guardarlo todo y, cuando hace falta, buscar los fragmentos más parecidos a la conversación actual. Es el motor que hay detrás de mucha memoria de IA impresionante, y miramos de cerca cómo lo hacen los sistemas de referencia. OpenClaw es retrieval-first: archiva todo y deja que el agente busque en ese almacén cuando necesita el historial. Hermes Agent mantiene un perfil pequeño y curado a mano siempre a la vista, y delega la recuperación más pesada a un servicio de memoria externo que trae los fragmentos relevantes en cada turno.
Ambos están bien construidos, y ambos son enfoques genuinamente buenos, para el montón creciente de notas de una sola persona. Pero cada uno, a su manera, se apoya en hacer coincidir texto con texto, y ahí es exactamente donde un espacio compartido los hace tropezar.
Considera lo más corriente que pasa en un grupo: dos personas distintas llamadas Mike.
No puedo distinguir al Mike con el que hablé ayer del Mike con el que hablé hace una semana; son personas distintas. Ni siquiera puedo distinguir de forma fiable al Mike de esta conversación del Mike de la anterior.
Busca «Mike» y no recuperas una persona; recuperas todos los pasajes que mencionan a un Mike, ordenados por lo parecidas que sean las palabras. La búsqueda puede ser impecable y la respuesta seguir siendo errónea, porque lo que volvió fue texto, no una persona. La coincidencia es buena para «¿de qué trata esto?». Un espacio compartido necesita «¿de quién trata esto, y sigue siendo cierto?», y esa es una pregunta sobre quién es alguien, no sobre qué palabras tiene cerca. La recuperación también envejece en silencio: una nota que dice «Mike está planeando un viaje a Tokyo» sigue siendo igual de fácil de encontrar mucho después de que el viaje haya terminado.
Podríamos haber seguido parcheando la búsqueda para que tuviera más en cuenta la identidad. En vez de eso, cambiamos lo que la memoria es.
Una memoria que puedes hojear, no solo consultar
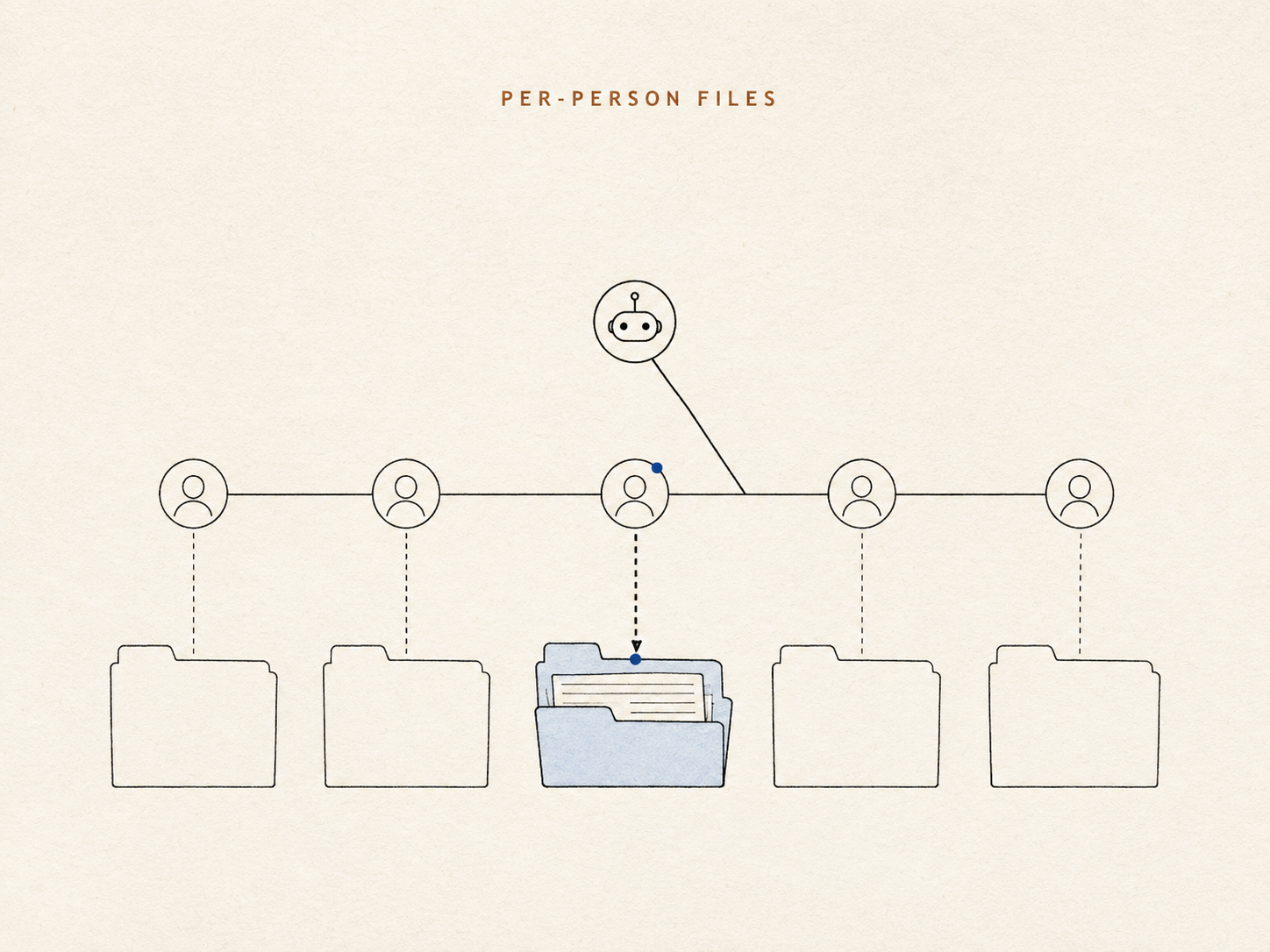
Le dimos a cada persona su propio pequeño conjunto de notas, guardadas como archivos corrientes que el agente puede abrir y leer directamente: sin índice oculto, sin puntuación de similitud de por medio. La identidad deja de ser una conjetura que la búsqueda tiene que recuperar; es simplemente de quién es esta carpeta. «El Mike de la sala» pasa a ser una consulta directa, no una apuesta.
Dentro de la memoria de cada persona, el agente toma una decisión por cada dato que registra: ¿esto debe estar delante de mí cada vez que hablo con esta persona, o solo cuando es relevante?
Piensa en un buen compañero de recepción que mantiene una ficha por cada cliente habitual. Un par de cosas van en el anverso de la ficha porque importan en cada conversación: cómo le gusta a alguien que le hablen, una alergia grave. Todo lo demás va en el cajón: real, recuperable, pero no pegado a tu frente. Mantener corto el anverso de la ficha es justamente el punto. Una memoria que saca a la superficie todo es, en la práctica, una memoria que no saca nada útil: el único dato que importa se ahoga entre los cien que no.
El resto espera en el cajón hasta que hace falta. Lo cual plantea el problema más difícil: lograr que el agente abra el cajón de verdad.
Una lección tomada de los agentes de programación
El fallo clásico de la memoria basada en archivos es que el agente decide que el cajón seguramente es irrelevante y nunca mira dentro. Así que la pregunta pasó a ser: ¿qué hace que un asistente vaya de forma fiable a comprobarlo?
La respuesta vino de un lugar inesperado: los agentes de IA que escriben software. Un agente de programación no construye un índice elaborado para encontrar una función dentro de un código grande. Hace lo que hace un ingeniero: busca en los archivos directamente, por texto plano, en el momento. Rápido, exacto, y el agente ya sabe hacerlo. Nosotros teníamos la misma forma —un conjunto de notas de texto— así que dejamos que nuestros agentes recordaran de la misma manera: cuando algo no está en el anverso de la ficha, ve a abrir los archivos y míralo.
Vale la pena dejar claro lo que esto no es: no reconstruimos en silencio «buscar en todo» con un nombre nuevo. No hay ningún índice intentando adivinar la relevancia. Hay un lugar para cada persona y una mirada directa cuando surge una pregunta concreta, el mismo movimiento que hace un ingeniero para encontrar una definición. Mantener los datos como notas planas y por persona nos da el quién y el sigue-siendo-cierto casi gratis; buscarlas directamente nos da la recuperación sin un índice que mantener sincronizado.
¿Funciona?
Lo probamos en vivo, con un agente real en conversaciones reales, observando qué recordaba y cómo.
Aguantó en lo que más importa. Los datos dejados «en el cajón» —una alergia alimentaria, el nombre de una mascota, un plan de viaje— se recuperaban correctamente al preguntar, porque el agente iba a mirar en vez de rendirse. Dados unos cuantos detalles en un solo mensaje, el agente los archivó con sensatez por su cuenta: puso una preferencia de comunicación y una alergia en el anverso de la ficha, y metió un detalle de proyecto acotado en el tiempo en el cajón, exactamente donde correspondía cada uno. Y cuando había memoria antigua de cuaderno único por ahí, el agente la reorganizó en la nueva forma por persona en mitad del trabajo normal, sin que se lo pidieran.
Estamos siendo deliberadamente prudentes con la palabra «funciona». Fueron resultados alentadores, no una vuelta de la victoria: un puñado de conversaciones con un modelo potente, no una tasa de éxito medida a lo largo de miles. El comportamiento que más nos intriga es si los modelos menos capaces siguen abriendo el cajón de forma fiable, o si recaen en el «seguramente es irrelevante». Y el sistema confía en el criterio del agente sobre qué va en el anverso de la ficha; pusimos un tope duro a cuánto puede caber ahí, pero un tope es una red de seguridad, no buen gusto. Enseñar buen gusto es el trabajo que queda abierto.
El punto de fondo
Lo que nos sorprendió fue lo poco que todo esto tenía que ver con la calidad de la recuperación. No nos alejamos de la búsqueda porque la búsqueda fuera mala. Nos movimos porque la unidad estaba equivocada. Un único cuaderno no tiene noción de quién; la búsqueda por pura similitud tampoco la tiene. Un espacio compartido convierte «quién, y sigue siendo cierto» en la primera pregunta, y lo más barato que la responde con honestidad es la cosa humilde en la que los agentes de programación ya confiaban: un conjunto de notas planas, uno por persona, que puedes leer y buscar directamente.
Eso nos deja con preguntas mejores que las del principio. ¿Cómo aguanta esto a medida que un agente llega a conocer a cientos de personas? ¿Se puede confiar en que un agente cure su propia memoria —que decida qué se queda en el anverso de la ficha y qué dejar desvanecer— o eso siempre necesita la mano de un humano en el mando? ¿Y hasta dónde viaja «diseñar primero para quién» más allá de las personas: a los proyectos, a los equipos, a los otros agentes con los que un asistente comparte una sala?
No creemos que la respuesta sea más memoria. Creemos que es una memoria que sabe para quién es. Cuando hay más de una persona en la sala, resulta que eso lo es todo.