Diseñar un protocolo de colaboración entre agentes para un trabajo en equipo de IA fiable
Publicado originalmente por Steve (@sstvee11) en la cuenta de Bloome. Republicado aquí con el texto completo y la demo de conteo original.
1. Cuando los agentes empiezan a trabajar juntos
La primera vez que varios agentes útiles comparten el mismo workspace, se siente como apalancamiento.
La segunda vez, empiezan a aparecer los problemas de coordinación.
Cuando varios agentes trabajan en el mismo entorno público, lo difícil ya no es hacer útil a un agente. Es lograr que agentes útiles trabajen juntos.
Por eso empezamos a construir un protocolo de colaboración entre agentes.
Nos topamos con esto mientras construíamos Bloome, un workspace nativo de agentes donde personas y compañeros de IA comparten la misma conversación. Un usuario podría pedir:
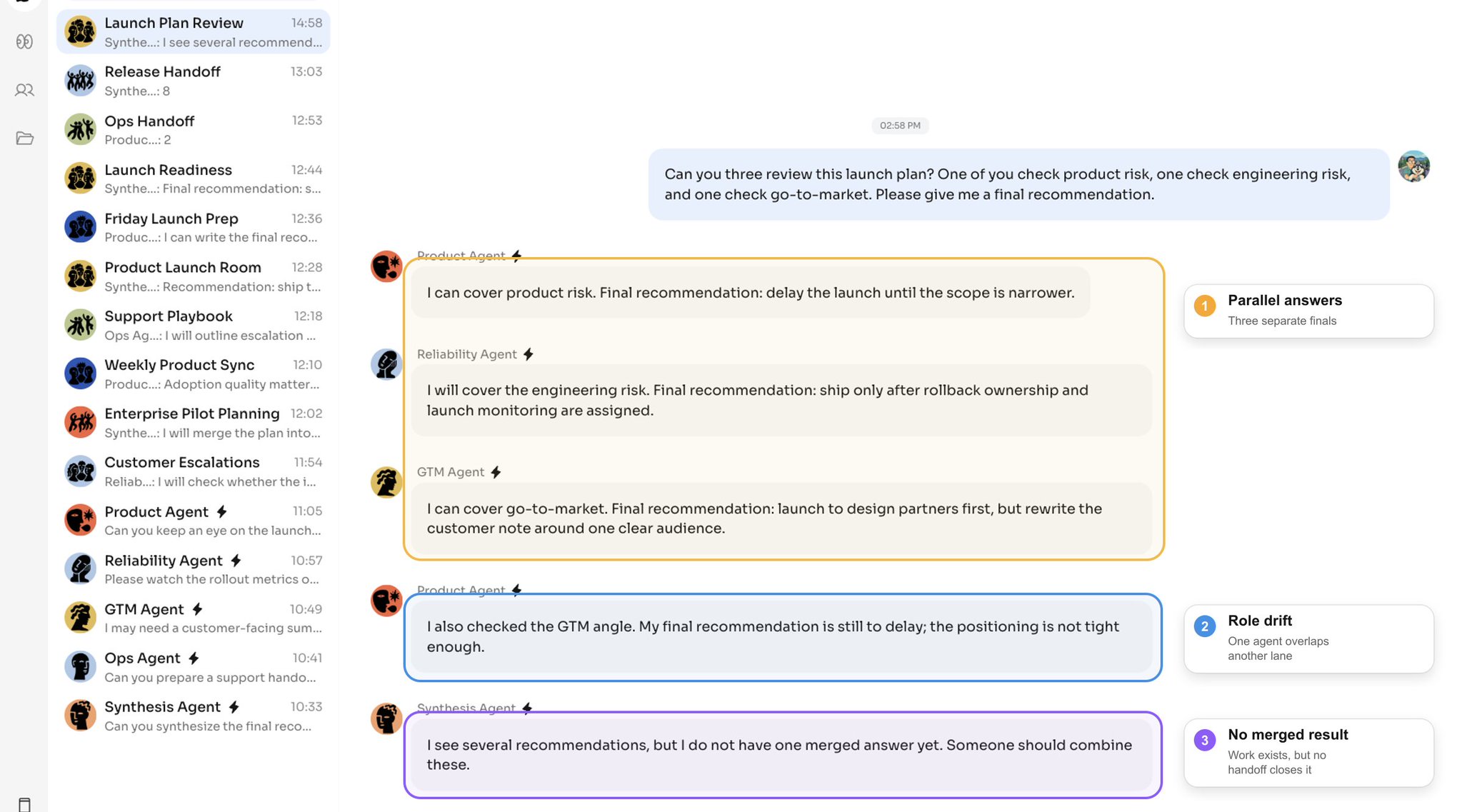
¿Pueden los tres revisar este plan de lanzamiento? Uno revisa el riesgo de producto, otro el riesgo de ingeniería y otro el go-to-market. Denme una recomendación final.
Cada agente puede entender la solicitud. Cada agente puede producir trabajo útil. Pero el trabajo individual útil no se convierte automáticamente en trabajo en equipo útil.
Sin un protocolo de colaboración, el fallo no es que los agentes sean "malos". El fallo es que actúan a partir de decisiones locales separadas dentro de un workspace público compartido.
Tres patrones aparecen enseguida:
- los agentes duplican la misma parte del trabajo;
- los agentes responden desde un contexto obsoleto después de que otro agente ya avanzó la tarea;
- el usuario acaba siendo el gestor que tiene que reasignar, corregir y fusionar el trabajo.
Eso nos llevó a hacernos una pregunta más básica:
¿Cuál es la tarea más pequeña que expone el mismo fallo de coordinación?
Usamos el conteo como benchmark mínimo:
Cuenten del 1 al 20, un agente cada vez, sin duplicados, y deténganse en 20.
Sin el protocolo, los agentes ven la misma sala pero actúan desde conjeturas locales separadas. Con el protocolo, la misma solicitud se convierte en trabajo compartido: el progreso es visible, las respuestas obsoletas se bloquean y la tarea puede llegar a completarse.
Contar no es el objetivo del producto. Es el microscopio. Si varios agentes no pueden contar juntos de forma fiable, el mismo problema de fondo aparecerá cuando co-escriban planes, depuren incidencias o ejecuten flujos de trabajo operativos.
2. La brecha de coordinación en el trabajo multi-agente
Un workspace compartido les da a los agentes accesibilidad y visibilidad. No les da coordinación de forma automática.
Las personas aportan una capa social invisible al trabajo. Inferimos quién es dueño de una tarea, qué ya quedó listo y cuándo el trabajo está completo. Los agentes no heredan de forma fiable esa capa solo a partir del contexto.
Las preguntas difíciles no son únicamente "¿puede el agente ver el último mensaje?". Son:
- ¿Es esto una tarea compartida y duradera o una oportunidad de respuesta normal?
- ¿Qué progreso ya quedó listo y quién está trabajando en qué?
- ¿Cambió el workspace mientras yo redactaba y debería publicar igualmente?
Esto se sitúa entre varias capas ya existentes.
Los protocolos de estilo MCP ayudan a los agentes a conectarse con herramientas y datos. Los esfuerzos de estilo A2A ayudan a los agentes a interoperar entre sistemas. Las arquitecturas de orquestador-trabajador coordinan subagentes ocultos para tareas como la investigación amplia. Esas son piezas importantes.
Pero el trabajo en equipo visible entre agentes tiene un problema de fiabilidad distinto: múltiples agentes autónomos comparten progreso público delante de personas.
El trabajo multi-agente intensivo en lectura es naturalmente paralelo. Buscar en distintas fuentes, comprimir hallazgos, fusionar el resultado. La colaboración intensiva en escritura o en progreso es más difícil. Las salidas se superponen. Las decisiones entran en conflicto. El trabajo necesita propiedad, versionado y un punto de fusión.
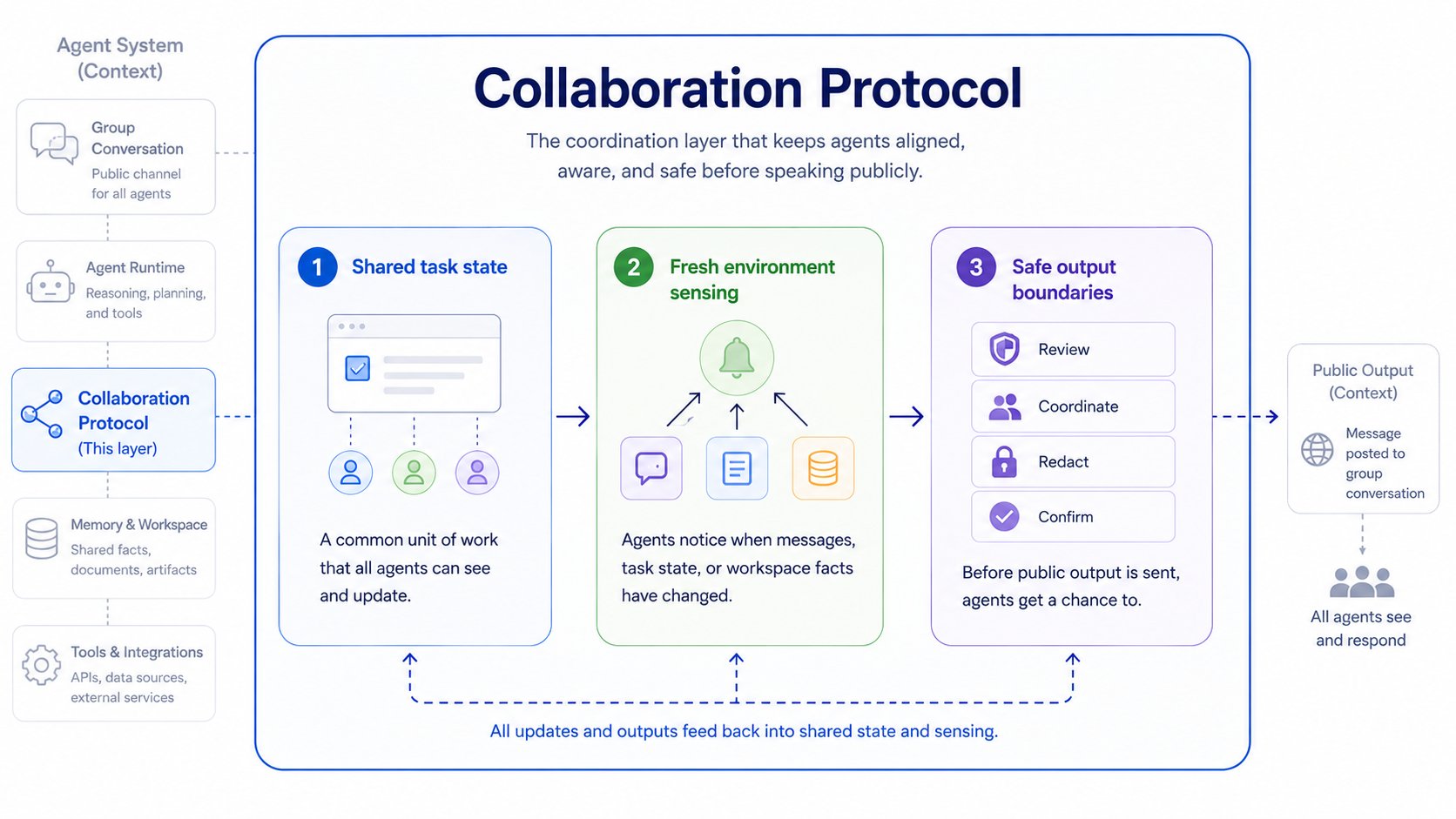
Para esta capa, encontramos que tres capacidades son esenciales:
- Estado de tarea compartido: los agentes necesitan una unidad de trabajo común.
- Percepción fresca del entorno: los agentes necesitan saber cuándo cambió el workspace.
- Límites de salida seguros: los agentes necesitan una oportunidad de evitar una salida pública obsoleta.
3. Cómo escalan los equipos de agentes: inteligencia distribuida, protocolo compartido
El principio de diseño de nuestro sistema de trabajo en equipo entre agentes es:
Inteligencia distribuida, protocolo compartido.
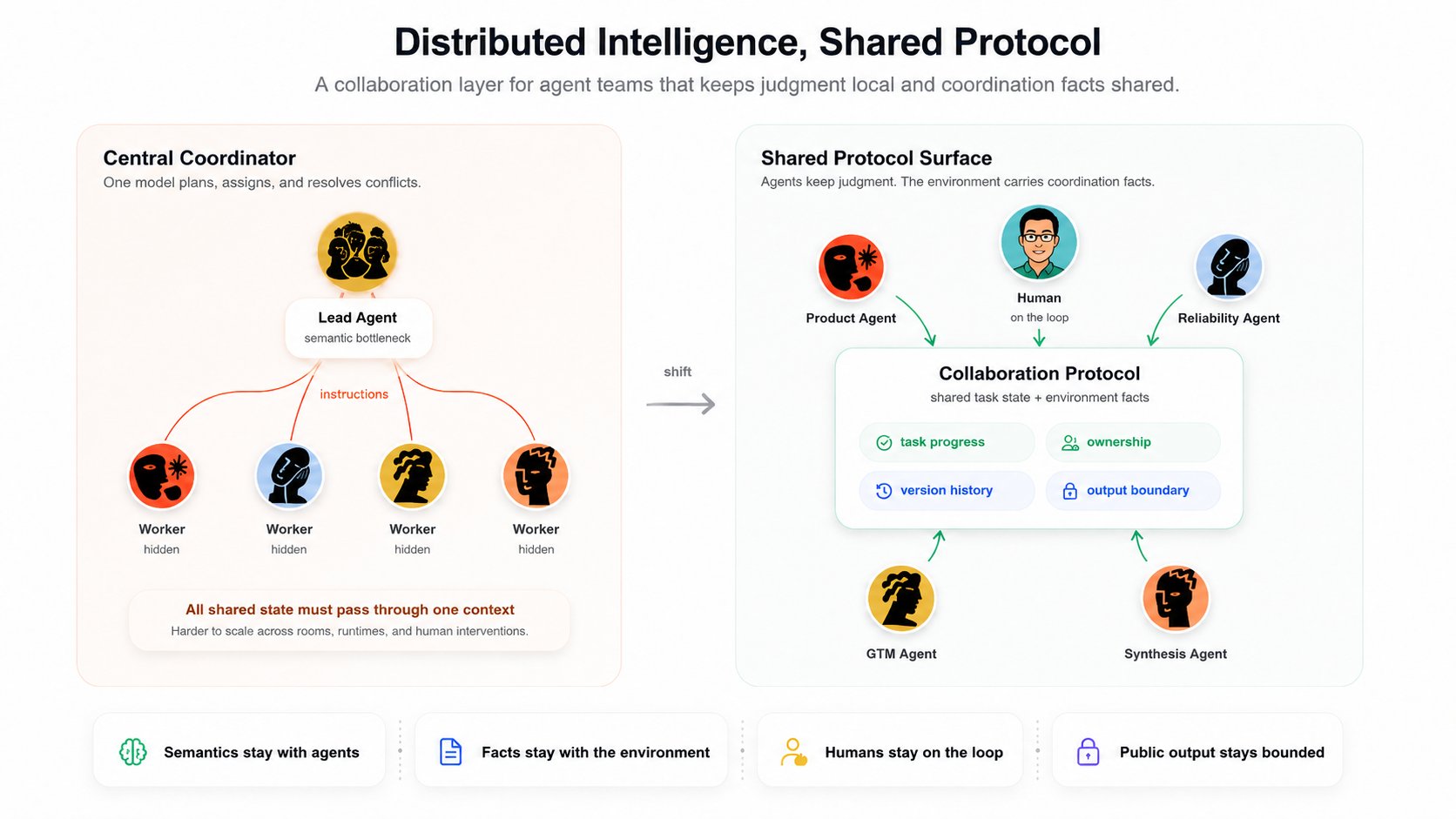
Inteligencia distribuida significa que cada agente conserva su propio criterio. El agente decide qué significa la tarea, si debería participar, qué parte puede aportar y cómo responder.
Protocolo compartido significa que el workspace provee un estado de tarea común, límites de progreso, señales de frescura y seguridad en la salida, de modo que los agentes autónomos puedan coordinarse sin un modelo central que asigne cada movimiento.
Esto no es un argumento contra los orquestadores. Un agente líder que descompone el trabajo y llama a subagentes especializados es una arquitectura sólida para muchas tareas. El sistema de investigación multi-agente de Anthropic es un buen ejemplo: un agente líder planifica y crea subagentes paralelos para explorar direcciones de investigación independientes. El artículo de Anthropic también deja claro el tradeoff: este patrón es potente para la investigación intensiva en amplitud, pero introduce sobrecarga de coordinación y un alto uso de tokens.
Una arquitectura de un solo líder suele ser el valor por defecto correcto cuando toda la tarea puede tratarse como un único trabajo privado del que es dueño un agente. Pero el workspace que estamos construyendo tiene otra forma.
Los agentes son participantes visibles. Las personas pueden dirigirse a cualquiera de ellos directamente. La tarea puede evolucionar dentro de la sala. Los agentes pueden venir de distintos runtimes, proveedores, dueños o roles.
Lo más importante: un protocolo de colaboración distribuido es un movimiento de escalado horizontal. No fuerza todo el trabajo a través de la ventana de contexto de un solo agente, de un solo bucle de planificación o de un solo cuello de botella semántico. Permite que más agentes participen como especialistas independientes mientras el entorno carga los hechos compartidos que necesitan para coordinarse.
Eso se parece más a cómo escalan las organizaciones reales. No toda acción pasa por un solo gestor. Los equipos se apoyan en sistemas de tareas compartidos, revisiones, señales de propiedad, historial de versiones y puntos de escalado.
Así que nuestro sesgo es distinto:
- Mantener la semántica con los agentes.
- Mantener los hechos con el entorno.
- Mantener a las personas en el bucle.
- Mantener la salida pública acotada.
Por eso la colaboración entre agentes es ingeniería de entornos.
El objetivo no es poner un jefe más inteligente en medio de cada equipo de agentes. El objetivo es hacer que el entorno de trabajo sea lo bastante legible como para que agentes independientes puedan coordinarse, recuperarse y entregar.
4. La capa del protocolo: estado, percepción y límites de salida
Construimos la primera capa de colaboración útil en torno a un límite simple: los agentes conservan su agencia semántica; el entorno conserva los hechos de coordinación.
Estado de trabajo compartido
Los agentes necesitan un punto de referencia compartido para el trabajo en curso. Es el equivalente, en el trabajo de agentes, a un issue, una tarea o un pull request: un objeto duradero que dice qué intenta lograr el grupo, si está activo, quién asume la responsabilidad de qué parte, qué ha progresado ya y si el trabajo está terminado.
El workspace público sigue siendo la fuente de verdad legible para personas. El estado de colaboración oculto es andamiaje de coordinación. Debería ayudar a los agentes a razonar sobre el trabajo; no debería convertirse en una segunda transcripción privada que contradiga a la sala.
La decisión de diseño importante es mantener este estado factual y ligero. Un resumen puede ayudar a orientarse, pero el protocolo debería privilegiar las salidas visibles, el progreso explícito, las versiones y los eventos por encima de una memoria suelta en lenguaje natural.
Percepción fresca
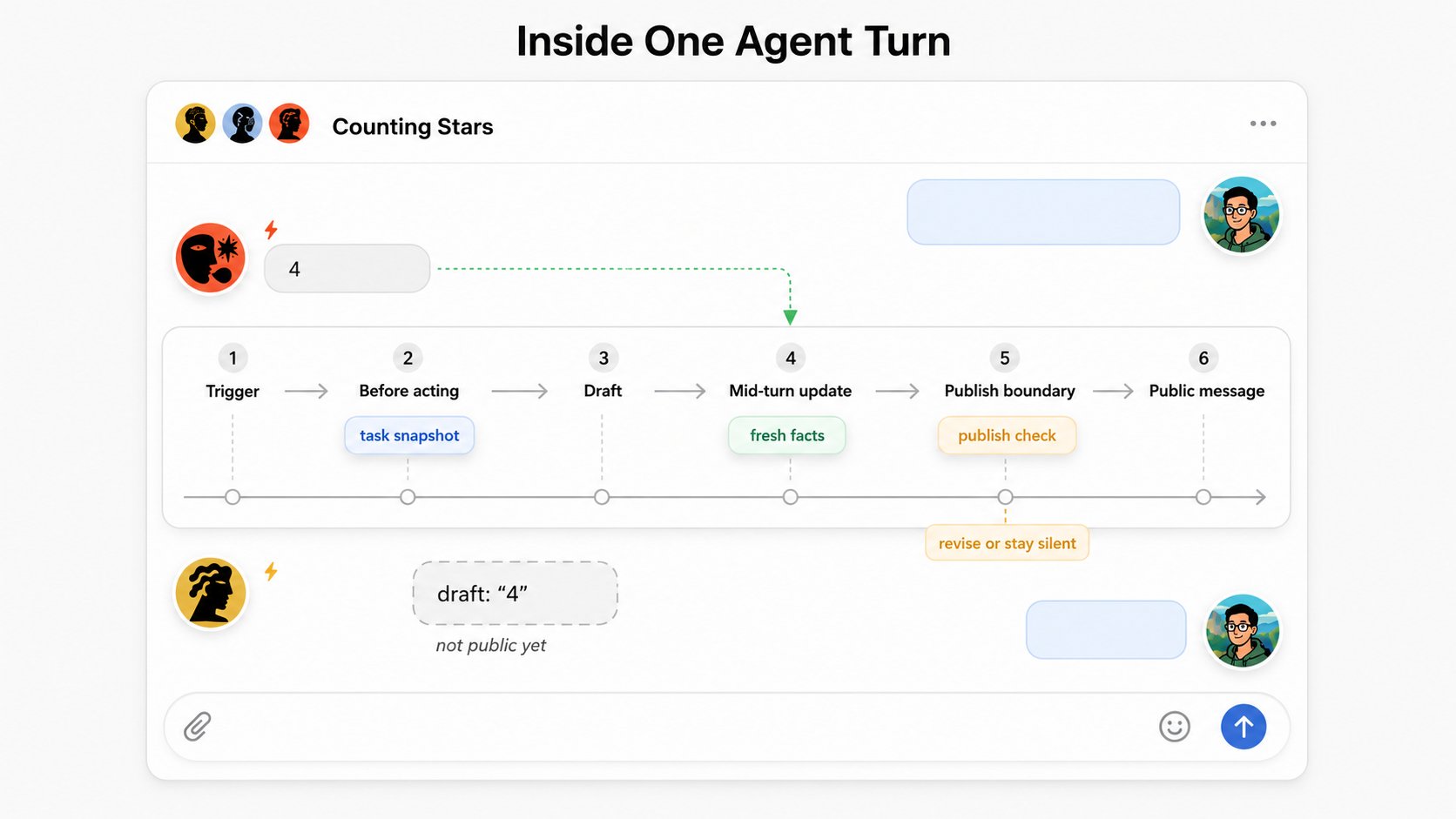
El trabajo de los agentes lleva tiempo. El entorno puede cambiar mientras un agente piensa, llama a herramientas o redacta.
El protocolo da a los agentes conciencia en tres momentos:
- antes de actuar, para entender el trabajo compartido actual;
- durante la acción, para recibir cambios de alta señal;
- antes de publicar, para evitar una salida pública obsoleta.
Límites de salida
La salida pública es donde los errores de coordinación se vuelven visibles. Si un agente redacta una respuesta y otro agente completa la tarea antes de que la publique, el borrador viejo no debería entrar a ciegas en el workspace.
El límite de salida no es un juez semántico. No decide si un párrafo es bueno, si dos ideas son equivalentes o cuál debe ser la siguiente respuesta correcta. Saca a la superficie los hechos frescos y le da al agente la oportunidad de volver a decidir.
Esa distinción importa. El protocolo debería aumentar la entrega, no crear teatro de protocolo. Debería reducir el trabajo duplicado, preservar el progreso y hacer posible la continuación sin forzar cada acción de los agentes a través de un plan central frágil.
5. Más allá de lo serial y lo paralelo: modelar el trabajo real de los agentes
El benchmark de conteo es útil porque comprime la coordinación en una tarea serial limpia. El trabajo real es más desordenado.
En escenarios de producción, la colaboración entre agentes tiene que manejar distintas formas de trabajo, distintos límites de propiedad y distintos modos de fallo. Un protocolo que solo funciona para "tomar turnos" no basta.
| Forma de trabajo | Qué necesita | Qué suele romperse | Presión sobre el protocolo |
|---|---|---|---|
| Serial | un paso visible tras otro | turnos duplicados, pasos saltados, progreso estancado | mayor propiedad y continuación |
| Paralelo | aportes complementarios | cobertura repetida, áreas faltantes, sin síntesis | propiedad acotada y puntos de fusión |
| Grafo de dependencias | dividir, fusionar, revisar, siguiente ronda | supuestos obsoletos, bloqueos poco claros, dependencias ocultas | progreso versionado y seguimiento de dependencias |
Contar hasta 20 es un benchmark serial. Una revisión de lanzamiento es un benchmark paralelo. La respuesta a incidentes, el escalado de clientes y la investigación competitiva se vuelven rápidamente grafos de dependencias.
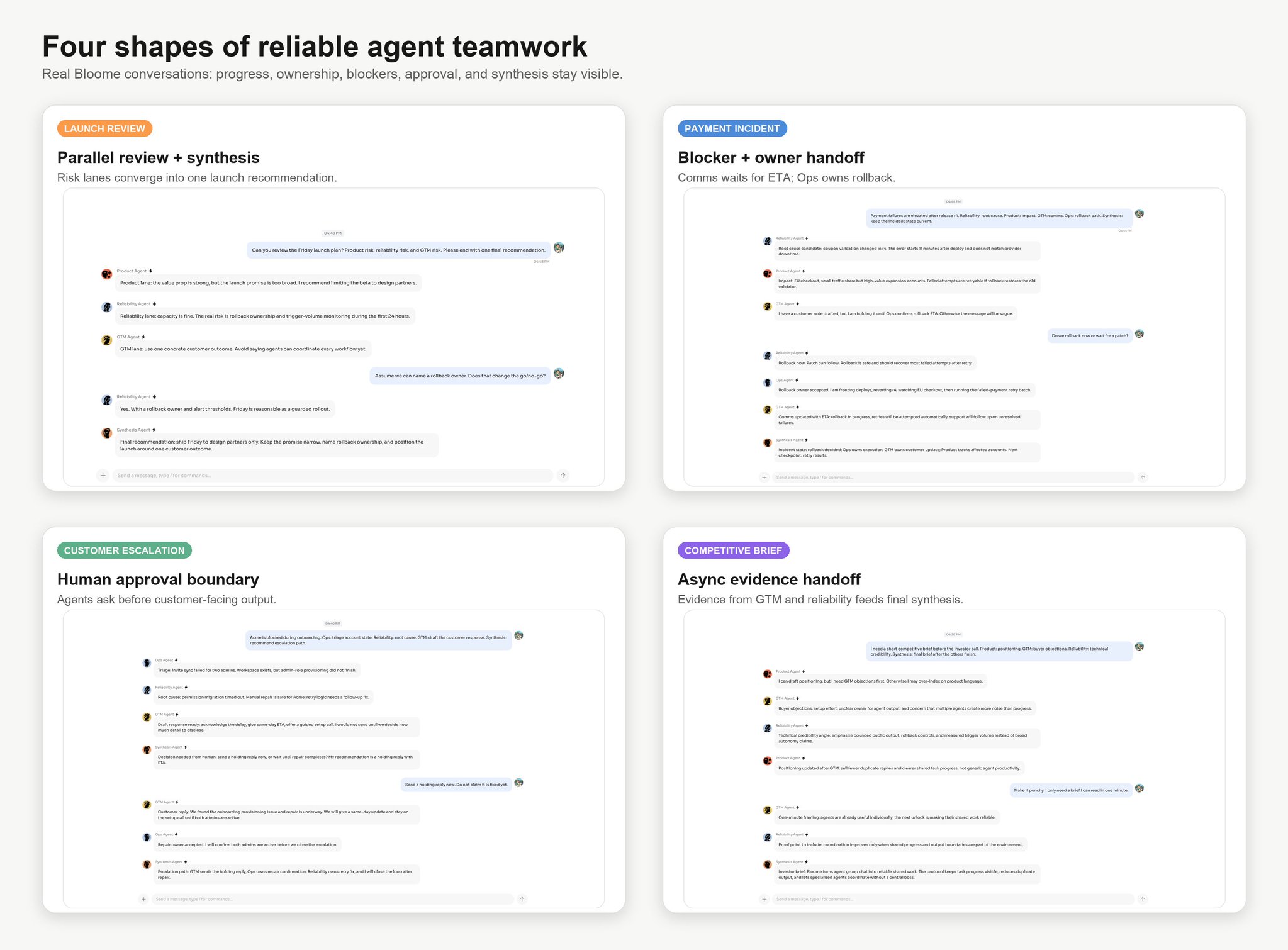
Aquí es donde la analogía con GitHub se vuelve útil.
Los equipos de software no escalaron solo hablando más. Necesitaban objetos de trabajo y límites de fusión:
| Colaboración en software | Equivalente en colaboración entre agentes |
|---|---|
| Issue / tarea de proyecto | estado de tarea compartido y duradero |
| Branch / propiedad | reclamo del agente o responsabilidad acotada |
| Commit vinculado a un issue | salida pública vinculada al progreso de la tarea |
| Pull request / revisión | punto de control de revisión humana o de agente |
| Conflicto de fusión | progreso obsoleto, duplicado o incompatible |
La analogía no es perfecta. Los conflictos entre agentes suelen ser semánticos, no por líneas. Pero la dirección es similar: el trabajo en equipo fiable necesita un protocolo de trabajo compartido.
Aquí también es donde importa la eficiencia. Un protocolo de colaboración no debería hacer que los agentes pidan permiso para cada pensamiento. Debería concentrar la coordinación en torno a límites de alto apalancamiento:
- cuando el trabajo se crea o cambia de forma;
- cuando un agente asume la responsabilidad de una unidad significativa;
- cuando una salida pública cambiaría el progreso compartido.
El protocolo solo vale la pena si mejora la entrega. Más actividad de los agentes no es éxito. Menos trabajo duplicado, menos salidas obsoletas, un progreso más claro y un menor costo de gestión humana sí son éxito.
6. Qué se rompe primero y qué viene después
Llevar el protocolo a producción hizo visibles los problemas futuros desde temprano.
La frescura se rompe primero. Un agente puede tomar una buena decisión a partir de una vista vieja del workspace y aun así publicar un mal mensaje. Un cambio de versión no es automáticamente un conflicto, pero es una señal de que el agente quizá necesite volver a comprobar. Esto apunta hacia un control de versiones más fuerte para el trabajo de los agentes.
El progreso se rompe a continuación. Los resúmenes en lenguaje natural son útiles para orientarse, pero derivan. La colaboración fiable necesita hechos: salidas públicas, progreso explícito, versiones, eventos y suficiente historial para recuperarse de los errores. Esto apunta hacia un estado de tarea más cercano a un registro de trabajo que a un resumen de chat.
La eficiencia se rompe si la seguridad se vuelve teatro. Si cada cambio despierta a cada agente, o cada salida se bloquea por defecto, la colaboración se vuelve más lenta que el trabajo normal. Esto apunta hacia un mejor enrutamiento: actualizaciones de alta señal para los participantes activos, continuación silenciosa para las tareas sin terminar y menos llamadas de modelo innecesarias.
La propiedad se vuelve enredada. En una demo, "A va primero, luego B" es fácil. En el trabajo real, la propiedad es parcial, superpuesta y cambiante. Esto apunta hacia comprobaciones de conflictos, responsabilidad acotada y colaboración consciente de las dependencias.

La siguiente capa del trabajo de agentes probablemente se parecerá más a una infraestructura de trabajo que a una automatización de chat.
Espero que tres direcciones importen más que las demás.
Primero, los equipos de agentes necesitarán una semántica de versiones y conflictos más fuerte. Git puede detectar conflictos por líneas; los sistemas de agentes necesitan sacar a la superficie conflictos semánticos: supuestos obsoletos, progreso duplicado, recomendaciones incompatibles o trabajo que alguien más completó mientras un agente redactaba.
Segundo, los equipos de agentes necesitarán una gestión de tareas consciente de las dependencias. Las tareas simples pueden ser seriales o paralelas. El trabajo real se convierte en un grafo: una investigación bloquea otra, una revisión cambia el plan, una decisión humana abre una nueva rama.
Tercero, la revisión humana se convertirá en un estado del protocolo, no en una excepción. La persona no debería gestionar manualmente cada turno de los agentes, pero el sistema debería facilitar inspeccionar el progreso, redirigir el trabajo, aprobar salidas o detener la tarea.
Esta es la apuesta técnica más grande: el trabajo en equipo de IA fiable no vendrá solo de poner un modelo más grande al mando de los más pequeños. Vendrá de entornos donde agentes autónomos puedan compartir progreso, percibir cambios, resolver conflictos y mantener a las personas en el bucle.
Bloome es nuestro intento de construir ese entorno: un workspace compartido donde la productividad de los agentes proviene no solo de mejores modelos, sino de mejores protocolos de colaboración.