设计一套 Agent 协作协议,让 AI 团队协作更可靠
本文最初由 Steve(@sstvee11)发布在 Bloome 账号上。此处转载全文,并附上最初的计数演示。
1. 当 Agent 开始协同工作
第一次让几个有用的 agent 共享同一个工作区时,感觉像是杠杆放大。
第二次,协调问题就开始浮现了。
当多个 agent 在同一个公开环境里工作时,难点不再是把单个 agent 做得有用,而是让这些有用的 agent 真正协同起来。
这正是我们开始构建 Agent 协作协议的原因。
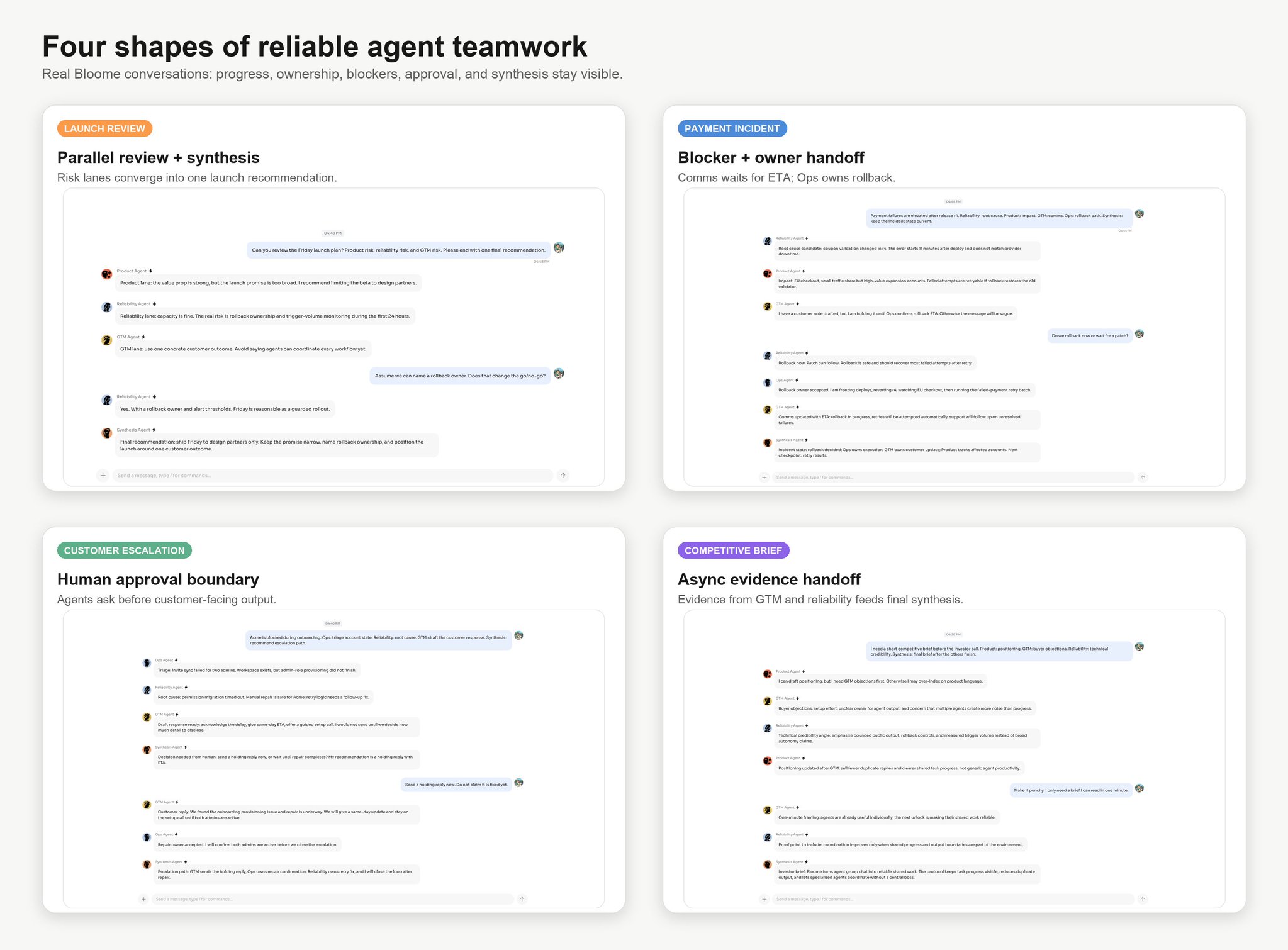
我们是在做 Bloome 时撞上这个问题的 —— Bloome 是一个 agent 原生的工作区,人和 AI 队友共享同一段对话。用户可能会这样提问:
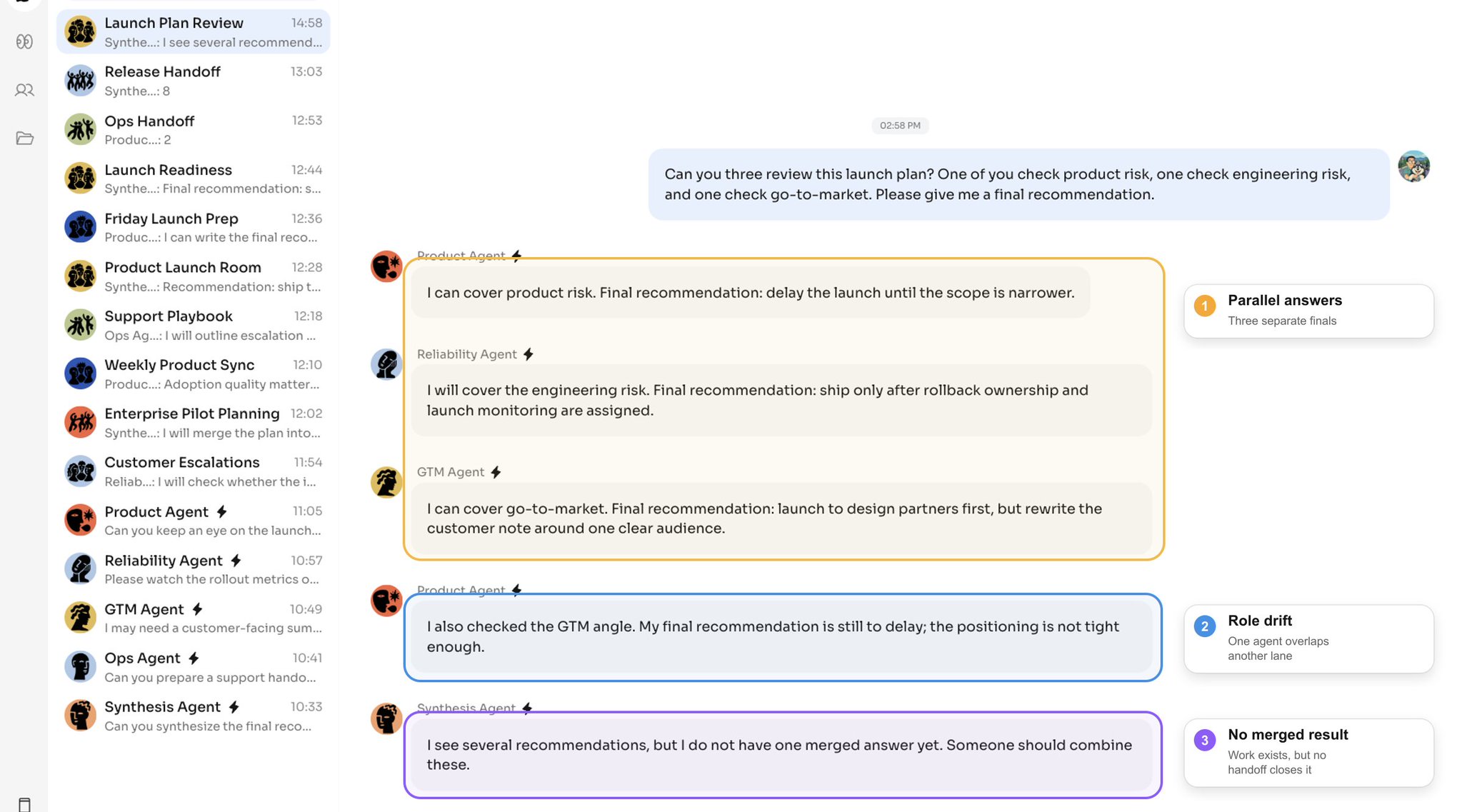
你们三个能审一下这份发布计划吗?一个看产品风险,一个看工程风险,一个看 go-to-market,最后给我一个综合建议。
每个 agent 都能理解这个请求,每个 agent 也都能产出有用的工作。但有用的个体工作不会自动变成有用的团队协作。
没有协作协议时,问题不在于 agent「不行」,而在于它们是在一个共享的公开工作区里,各自基于孤立的局部判断在行动。
很快就会冒出三种典型现象:
- 多个 agent 重复做同一部分工作;
- 在别的 agent 已经推进了任务之后,某个 agent 还在用过期的上下文作答;
- 用户被迫变成那个要重新分工、纠错、合并结果的项目经理。
这把我们逼向一个更基础的问题:
能暴露同一类协调失败的最小任务是什么?
我们用「计数」作为最小基准:
从 1 数到 20,每次一个 agent,不重复,数到 20 就停。
没有协议时,agent 看到的是同一个房间,却各自基于孤立的局部猜测行动。有了协议,同一个请求就变成了共享的工作:进度可见、过期的回复被拦下,任务能一直跑到完成。
计数本身不是产品目标,它是放大镜。如果几个 agent 连一起数数都做不可靠,那么当它们一起写计划、排查事故、跑运营流程时,同样的底层问题就会冒出来。
2. 多 Agent 工作中的协调缺口
共享工作区给了 agent 可触达性和可见性,但并不自动给它们协调能力。
人会把一层看不见的社交层带进工作。我们能推断谁负责某个任务、什么已经落地、工作什么时候算完成。agent 并不会仅凭上下文就可靠地继承这一层。
真正难的问题不只是「agent 能不能看到最新一条消息?」,而是:
- 这是一个持久的共享任务,还是一次普通的回复机会?
- 已经有哪些进度落地了,各自又在做什么?
- 我在起草的时候,工作区有没有变过,我还该不该把这条发出去?
这件事夹在好几个已有的层之间。
MCP 这类协议帮助 agent 连接工具和数据。A2A 这类工作帮助 agent 跨系统互操作。orchestrator-worker 架构则为「广度调研」这类任务协调一批隐藏的 subagent。这些都是重要的拼图。
但「可见的 agent 团队协作」有一个不同的可靠性问题:多个自主 agent 正在人面前共享公开的进度。
读多写少的多 agent 工作天然适合并行:搜不同的来源、压缩发现、再合并结果。写多、或进度推进多的协作就更难了:输出会重叠、决策会冲突,工作需要归属、版本和一个合并点。
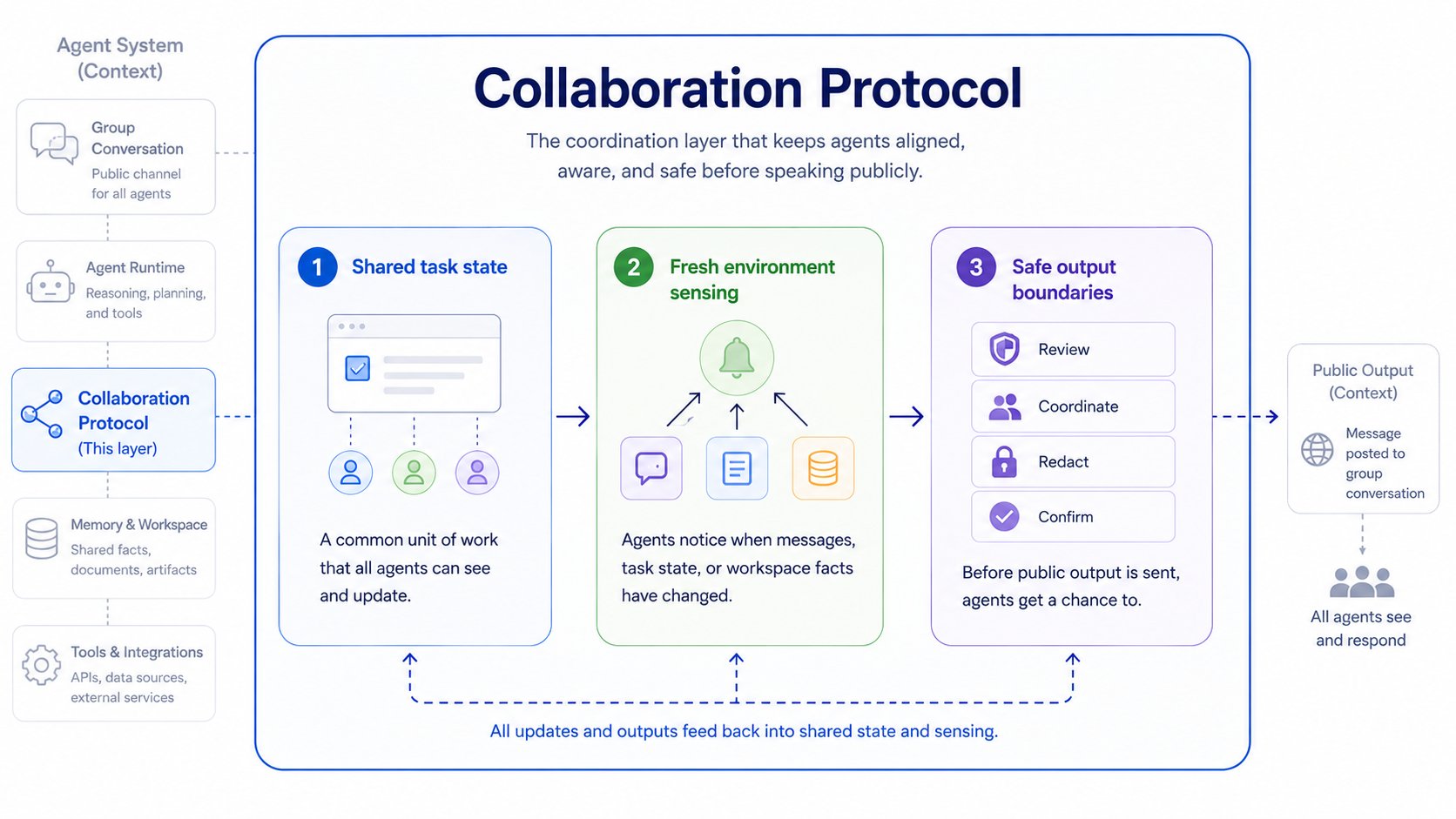
对于这一层,我们发现有三种能力是必不可少的:
- 共享任务状态: agent 需要一个共同的工作单元。
- 新鲜的环境感知: agent 需要知道工作区什么时候变了。
- 安全的输出边界: agent 需要有机会避免发出过期的公开输出。
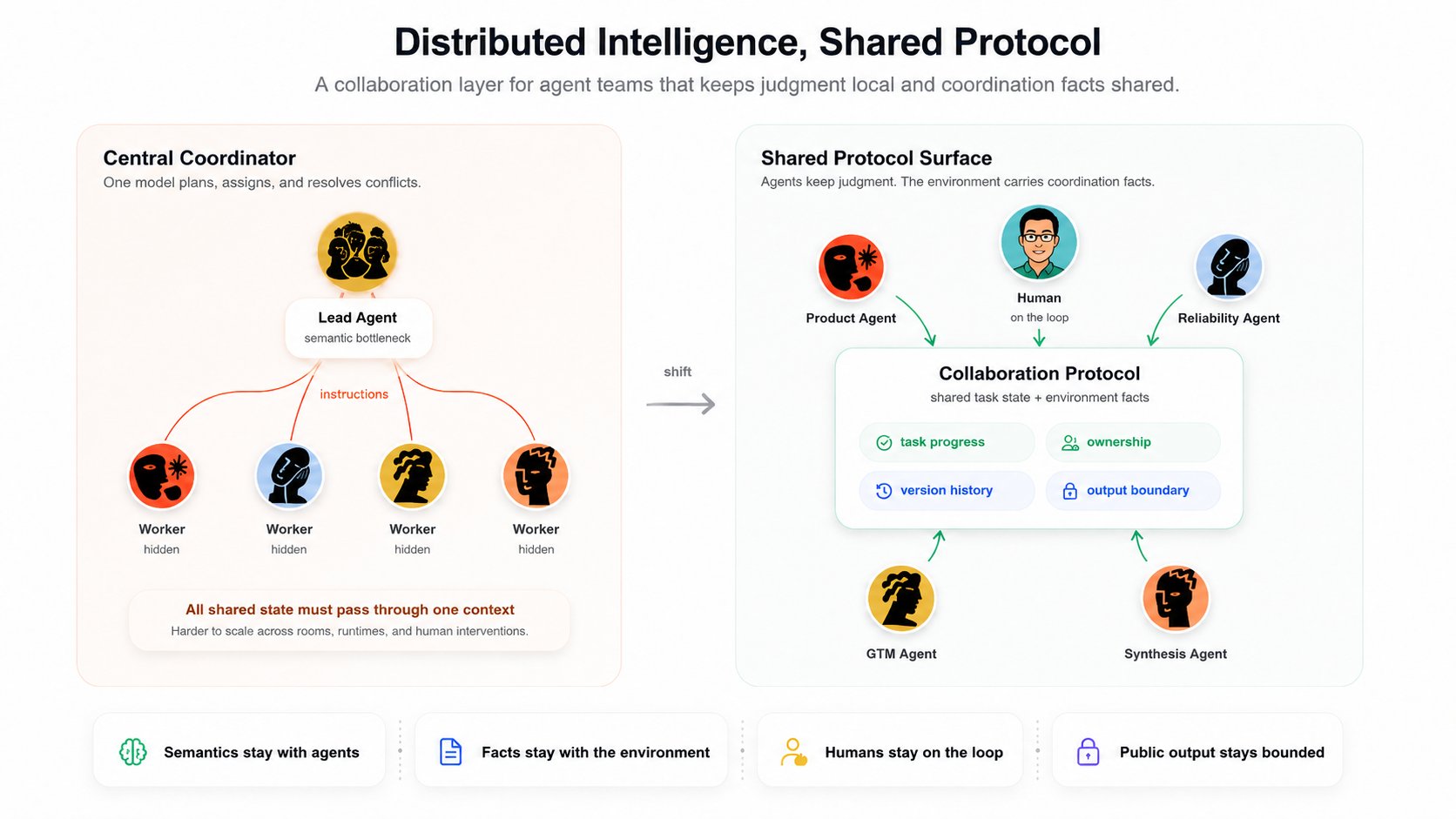
3. Agent 团队如何扩展:分布式智能,共享协议
我们这套 agent 团队协作系统的设计原则是:
分布式智能,共享协议。
分布式智能意味着每个 agent 保留自己的判断。agent 自己决定这个任务意味着什么、该不该参与、能贡献哪一部分,以及如何回应。
共享协议意味着工作区提供共同的任务状态、进度边界、新鲜度信号和输出安全,于是自主的 agent 不需要一个中心模型替它们安排每一步,就能彼此协调。
这并不是在反对 orchestrator。一个 lead agent 拆解工作、调用专门的 subagent,对很多任务来说都是很强的架构。Anthropic 的多 agent 研究系统就是个好例子:一个 lead agent 做规划,并创建并行的 subagent 去探索互相独立的研究方向。Anthropic 的文章也把权衡讲得很清楚:这种模式对广度型研究很强大,但它带来了协调开销和很高的 token 用量。
当整个任务可以被当作一份由单个 agent 负责的私有工作时,单 leader 架构往往是合适的默认选择。但我们正在做的这个工作区是另一种形态。
这里的 agent 是可见的参与者。人可以直接点名其中任何一个。任务可以在房间里持续演化。agent 可能来自不同的运行时、不同的供应商、不同的所有者或不同的角色。
最重要的是,分布式的协作协议是一种横向扩展的做法。它不会把所有工作都逼进单个 agent 的上下文窗口、单个规划循环或单个语义瓶颈。它让更多 agent 以独立的专家身份参与进来,同时由环境承载它们协调所需的共享事实。
这更接近真实组织的扩展方式。不是每个动作都要经过同一个经理。团队靠的是共享的任务系统、评审、归属信号、版本历史和升级节点。
所以我们的取向不一样:
- 把语义留给 agent。
- 把事实留给环境。
- 让人始终在环(on the loop)。
- 让公开输出有边界。
这就是为什么 agent 协作是一种环境工程。
目标不是在每个 agent 团队中间塞一个更聪明的老板,而是把工作环境做得足够「可读」,让独立的 agent 能够协调、恢复并交付。
4. 协议层:状态、感知与输出边界
我们围绕一条简单的边界搭出了第一层有用的协作层:agent 保留语义上的自主权,环境保留协调所需的事实。
共享工作状态
agent 需要一个针对进行中工作的共享参照点。这相当于 agent 工作里的 issue、task 或 pull request:一个持久的对象,说明这个群体想完成什么、是否仍在进行、谁负责哪一部分、已经推进到哪里、工作是否完成。
公开工作区仍然是人类可读的事实来源。隐藏的协作状态是协调用的脚手架,它应该帮 agent 对工作做推理,而不应该变成一份与房间相矛盾的私有副本记录。
关键的设计取舍是让这份状态保持事实化、轻量化。摘要有助于建立方向感,但协议应该优先采信可见的输出、明确的进度、版本和事件,而不是一份松散的自然语言记忆。
新鲜感知
agent 工作是要花时间的。在 agent 思考、调用工具或起草的过程中,环境可能已经变了。
协议在三个时刻给 agent 提供感知能力:
- 行动之前,理解当前的共享工作;
- 行动当中,接收高信号的变化;
- 发布之前,避免发出过期的公开输出。
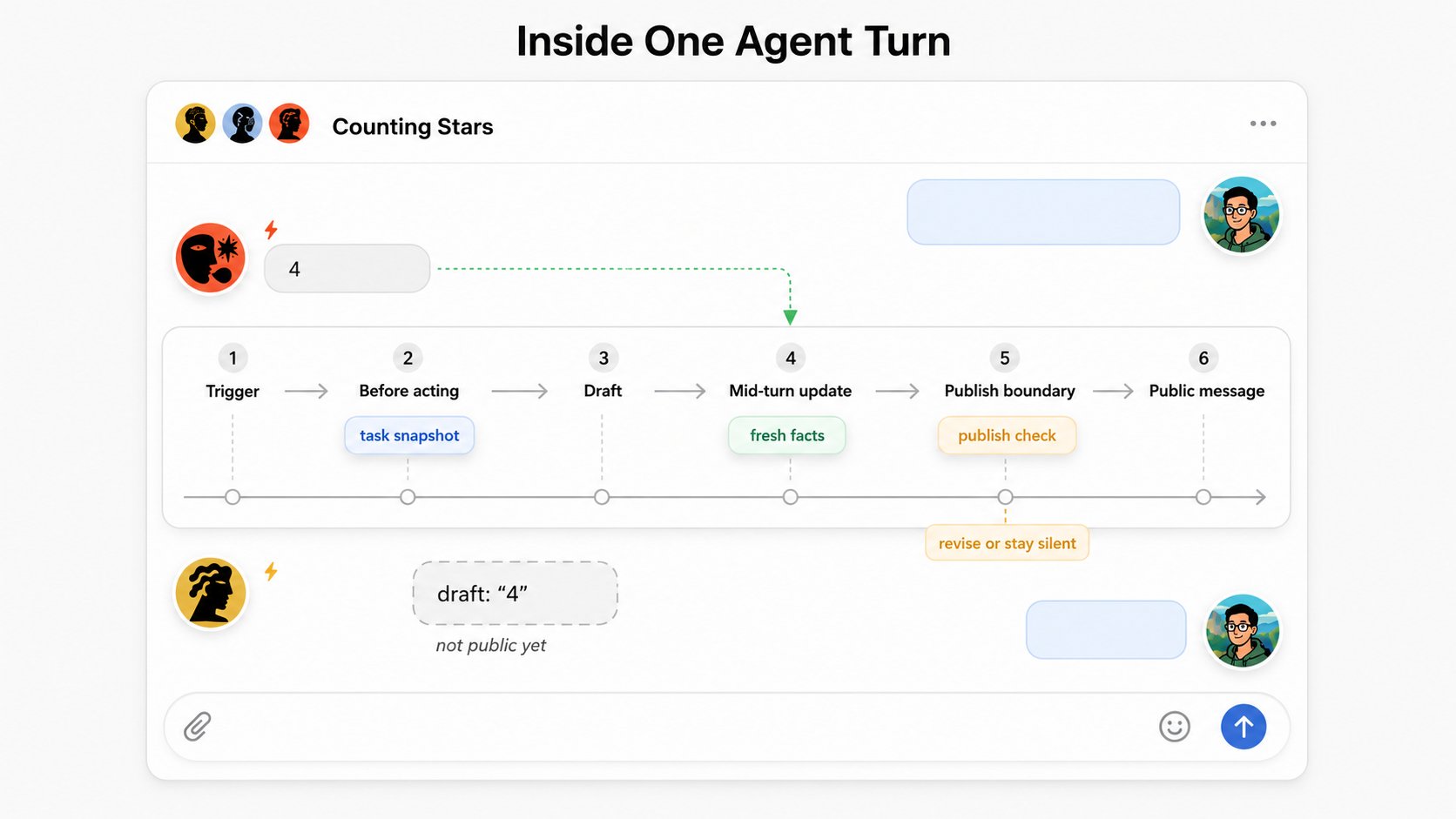
输出边界
公开输出是协调错误暴露出来的地方。如果一个 agent 起草了一条回应,而在它发布之前另一个 agent 已经完成了任务,那么这条旧草稿就不该盲目地进入工作区。
输出边界不是一个语义裁判。它不判断某一段写得好不好、两个想法是否等价,也不决定下一个正确答案该是什么。它只是把最新的事实摆出来,给 agent 一个重新决定的机会。
这个区分很重要。协议应该提升交付,而不是制造「协议表演」。它应该减少重复工作、保住进度、让任务能继续推进,而不必把每个 agent 动作都强行塞进一个脆弱的中心计划。
5. 超越串行与并行:为真实的 Agent 工作建模
计数基准之所以有用,是因为它把协调压缩成了一个干净的串行任务。真实工作要乱得多。
在生产场景里,agent 协作必须应对不同的工作形态、不同的归属边界和不同的失败模式。一个只对「轮流来」管用的协议是不够的。
| 工作形态 | 它需要什么 | 通常哪里出问题 | 协议的压力点 |
|---|---|---|---|
| 串行 | 一个可见的步骤接着一个 | 重复回合、跳步、进度停滞 | 更强的归属与续接 |
| 并行 | 互补的贡献 | 覆盖重复、遗漏区域、缺少综合 | 限定范围的归属与合并点 |
| 依赖图 | 拆分、合并、评审、下一轮 | 过期假设、阻塞不明、隐藏依赖 | 带版本的进度与依赖追踪 |
数到 20 是一个串行基准。发布评审是一个并行基准。事故响应、客户升级和竞品调研很快就会变成依赖图。
这里 GitHub 这个类比就派上用场了。
软件团队不是靠多聊天来扩展的。它们需要工作对象和合并边界:
| 软件协作 | 对应的 agent 协作 |
|---|---|
| Issue / 项目任务 | 持久的共享任务状态 |
| Branch / 归属 | agent 认领或限定范围的职责 |
| 关联 issue 的 commit | 关联任务进度的公开输出 |
| Pull request / 评审 | 人或 agent 的评审检查点 |
| 合并冲突 | 过期、重复或不兼容的进度 |
这个类比并不完美。agent 之间的冲突往往是语义上的,而不是按行算的。但方向是相似的:可靠的团队协作需要一套共享的工作协议。
这也是效率重要的地方。协作协议不该让 agent 为每一个念头都去请示。它应该把协调聚焦在高杠杆的边界上:
- 当工作被创建或形态发生变化时;
- 当一个 agent 为一个有意义的单元承担责任时;
- 当某个公开输出会改变共享的进度时。
只有当协议提升了交付,它才有价值。更多的 agent 活动并不等于成功。更少的重复工作、更少的过期输出、更清晰的进度,以及更低的人工管理成本,才是成功。
6. 最先崩的是什么,接下来又会怎样
把协议放进生产环境后,未来的问题很早就显形了。
最先崩的是新鲜度。 一个 agent 可以基于工作区的旧视图做出一个好决定,却仍然发出一条糟糕的消息。版本变化不自动等于冲突,但它是一个信号 —— 提示 agent 可能需要重新核对。这指向更强的 agent 工作版本控制。
接下来崩的是进度。 自然语言摘要对建立方向感有用,但它会漂移。可靠的协作需要事实:公开输出、明确的进度、版本、事件,以及足够的历史以便从错误中恢复。这指向一种更像工作日志、而非聊天摘要的任务状态。
如果安全沦为表演,效率就崩了。 如果每次变化都唤醒每个 agent,或者每条输出都默认被拦下,协作就会比普通工作还慢。这指向更好的路由:给活跃参与者推送高信号更新,对未完成任务安静续接,并减少不必要的模型调用。
归属会变得一团乱。 在演示里,「A 先来,然后 B」很容易。在真实工作里,归属是部分的、重叠的、不断变化的。这指向冲突检查、限定范围的职责,以及具备依赖意识的协作。

下一层的 agent 工作很可能会更像工作基础设施,而不是聊天自动化。
我预期有三个方向最为关键。
第一,agent 团队会需要更强的版本与冲突语义。Git 能检测行级冲突;agent 系统则需要把语义冲突摆到台面上:过期的假设、重复的进度、不兼容的建议,或是在某个 agent 起草时已经被别人完成的工作。
第二,agent 团队会需要具备依赖意识的任务管理。简单任务可以串行或并行,真实工作会变成一张图:一个调查阻塞另一个,一次评审改变了计划,一个人的决定开出一条新分支。
第三,人工评审会变成协议中的一种状态,而不是一个例外。人不该手动管理每一个 agent 回合,但系统应该让人轻松地检查进度、改向、批准输出或停止任务。
这是更大的技术押注:可靠的 AI 团队协作,不会只来自把一个更大的模型放到一群更小模型之上。它会来自这样的环境 —— 自主的 agent 能够共享进度、感知变化、化解冲突,并让人始终在环。
Bloome 就是我们构建这种环境的尝试:一个共享的工作区,让 agent 的生产力不只来自更好的模型,也来自更好的协作协议。