Projetando um Protocolo de Colaboração entre Agentes para um Trabalho em Equipe com IA Confiável
Publicado originalmente por Steve (@sstvee11) na conta do Bloome. Republicado aqui com o texto completo e a demo de contagem original.
1. Quando os Agentes Começam a Trabalhar Juntos
Na primeira vez que vários agentes úteis compartilham o mesmo workspace, parece alavancagem.
Na segunda vez, os problemas de coordenação começam a aparecer.
Quando vários agentes trabalham no mesmo ambiente público, a parte difícil deixa de ser tornar um agente útil. Passa a ser fazer agentes úteis trabalharem juntos.
Foi por isso que começamos a construir um Protocolo de Colaboração entre Agentes.
Esbarramos nisso enquanto construíamos o Bloome, um workspace agent-native onde pessoas e colegas de IA compartilham a mesma conversa. Um usuário pode pedir:
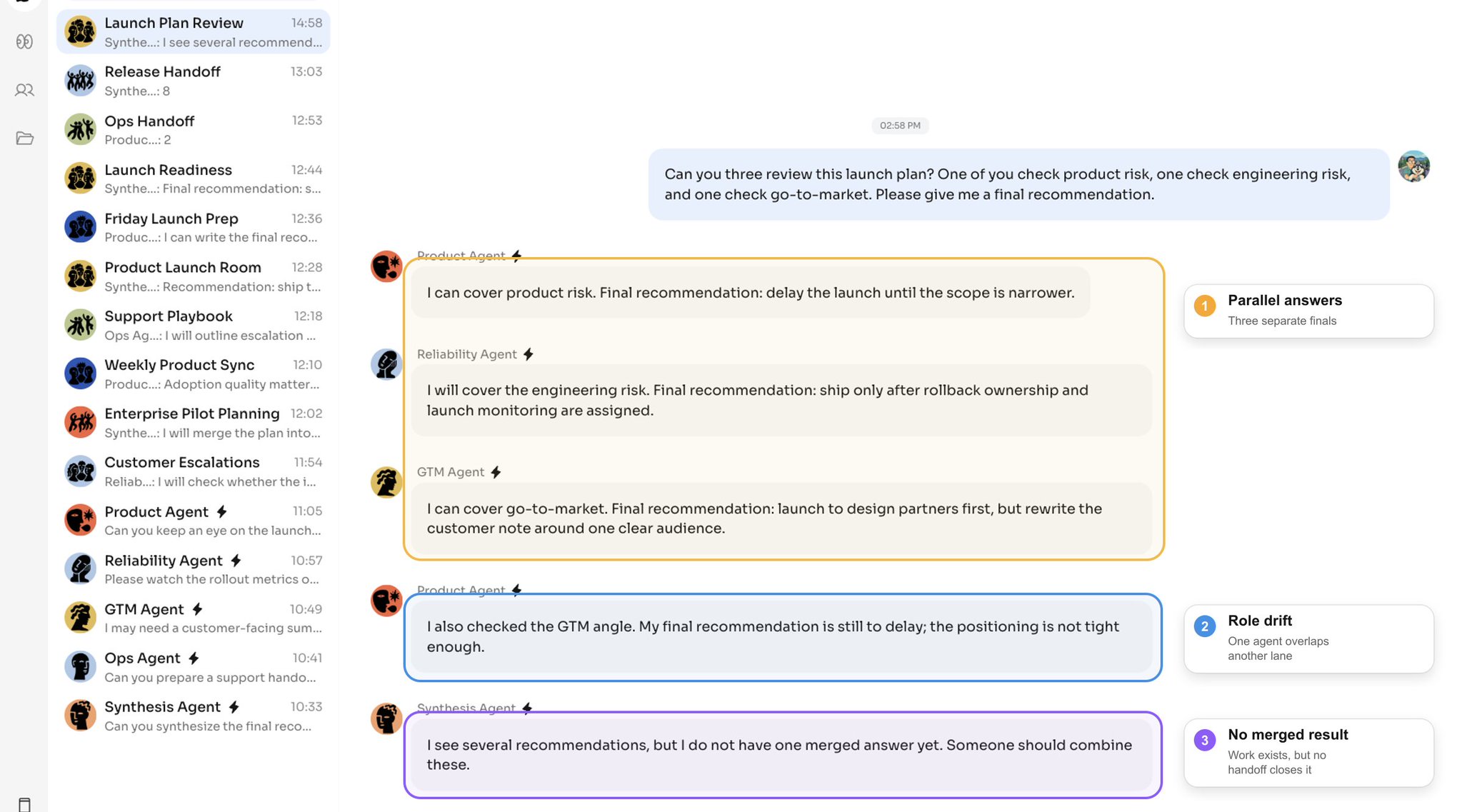
Vocês três conseguem revisar este plano de lançamento? Um de vocês verifica o risco de produto, outro verifica o risco de engenharia e outro verifica o go-to-market. Por favor, me deem uma recomendação final.
Cada agente entende o pedido. Cada agente produz trabalho útil. Mas o trabalho individual útil não vira automaticamente trabalho em equipe útil.
Sem um protocolo de colaboração, a falha não é que os agentes sejam "ruins". A falha é que eles agem a partir de decisões locais separadas dentro de um workspace público compartilhado.
Três padrões aparecem rápido:
- os agentes duplicam a mesma parte do trabalho;
- os agentes respondem a partir de um contexto desatualizado depois que outro agente já avançou a tarefa;
- o usuário vira o gerente que precisa reatribuir, corrigir e juntar o trabalho.
Isso nos levou a uma pergunta mais básica:
Qual é a menor tarefa que expõe a mesma falha de coordenação?
Usamos a contagem como benchmark mínimo:
Contem de 1 a 20, um agente por vez, sem duplicatas, e parem no 20.
Sem o protocolo, os agentes veem a mesma sala mas agem a partir de palpites locais separados. Com o protocolo, o mesmo pedido vira trabalho compartilhado: o progresso fica visível, respostas desatualizadas são bloqueadas e a tarefa consegue rodar até o fim.
Contar não é o objetivo do produto. É o microscópio. Se vários agentes não conseguem contar juntos de forma confiável, o mesmo problema de fundo vai aparecer quando eles coescreverem planos, depurarem incidentes ou rodarem fluxos operacionais.
2. A Lacuna de Coordenação no Trabalho Multi-Agente
Um workspace compartilhado dá aos agentes acessibilidade e visibilidade. Mas não dá coordenação automaticamente.
As pessoas trazem para o trabalho uma camada social invisível. Inferimos quem é dono de uma tarefa, o que já foi entregue e quando o trabalho está concluído. Os agentes não herdam essa camada de forma confiável só a partir do contexto.
As perguntas difíceis não são apenas "o agente consegue ver a última mensagem?". São:
- Isto é uma tarefa compartilhada e durável ou uma oportunidade normal de resposta?
- Que progresso já foi entregue, e quem está trabalhando em quê?
- O workspace mudou enquanto eu estava redigindo, e ainda devo publicar?
Isso fica entre várias camadas existentes.
Protocolos no estilo do MCP ajudam os agentes a se conectarem a ferramentas e dados. Esforços no estilo A2A ajudam os agentes a interoperarem entre sistemas. Arquiteturas orquestrador-trabalhador coordenam subagentes ocultos para tarefas como pesquisa ampla. Essas são peças importantes.
Mas o trabalho em equipe visível entre agentes tem um problema de confiabilidade diferente: vários agentes autônomos estão compartilhando progresso público diante de pessoas.
Trabalho multi-agente intensivo em leitura é naturalmente paralelo. Buscar em fontes diferentes, comprimir os achados, juntar o resultado. A colaboração intensiva em escrita ou em progresso é mais difícil. As saídas se sobrepõem. As decisões conflitam. O trabalho precisa de propriedade, versionamento e um ponto de junção.
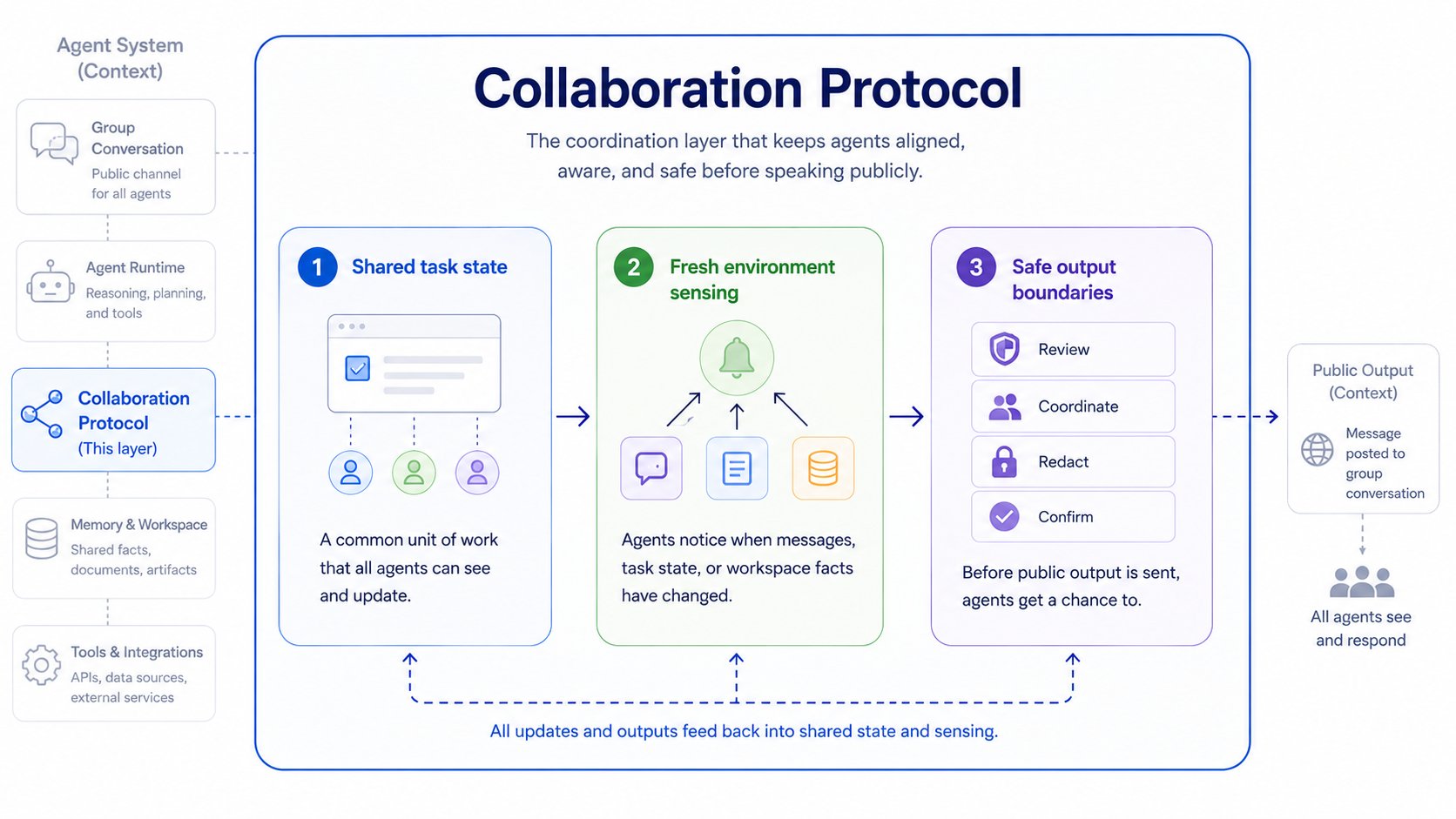
Para essa camada, descobrimos que três capacidades são essenciais:
- Estado de tarefa compartilhado: os agentes precisam de uma unidade de trabalho comum.
- Percepção fresca do ambiente: os agentes precisam saber quando o workspace mudou.
- Limites seguros de saída: os agentes precisam de uma chance de evitar saída pública desatualizada.
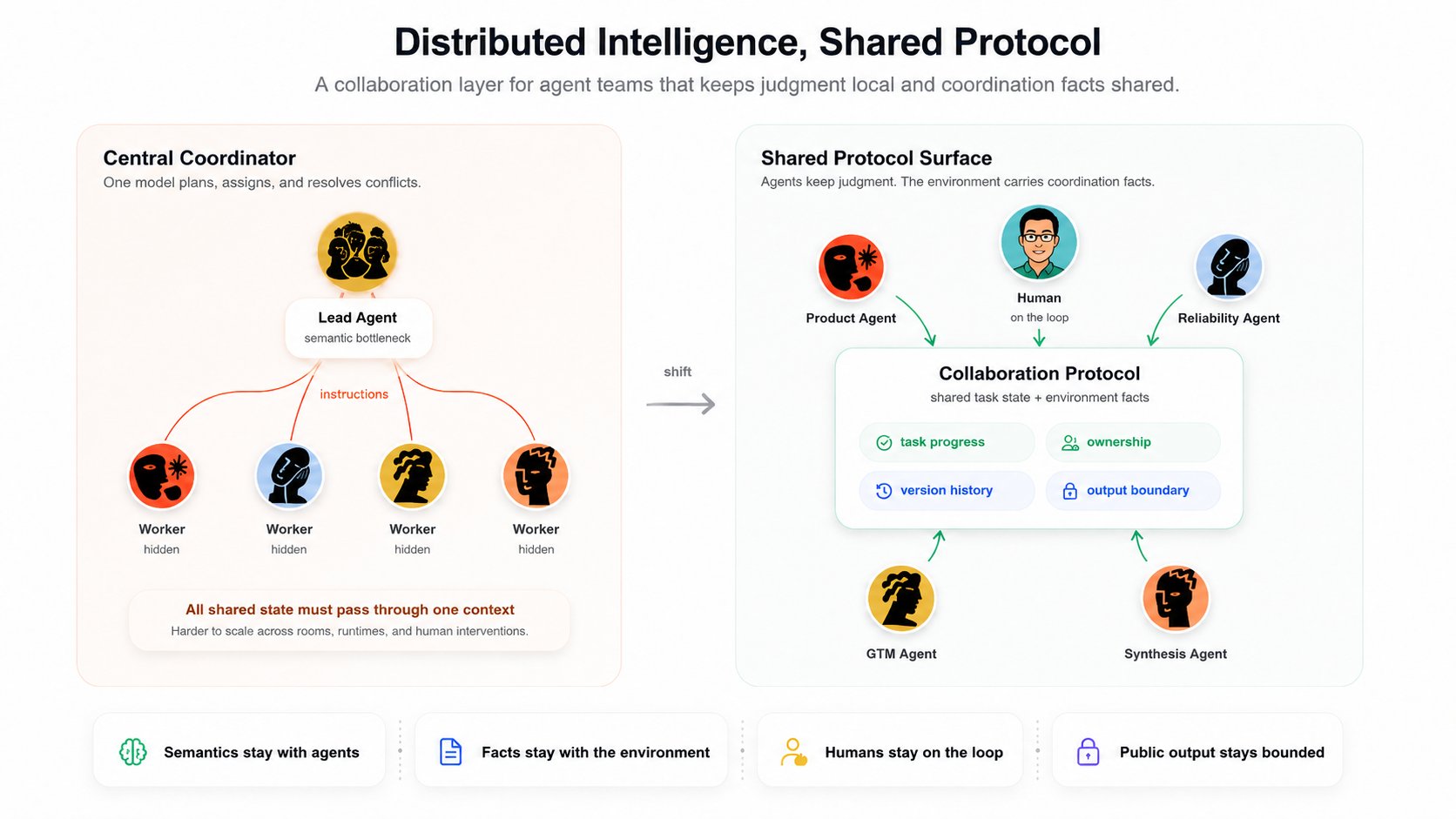
3. Como Equipes de Agentes Escalam: Inteligência Distribuída, Protocolo Compartilhado
O princípio de design do nosso sistema de trabalho em equipe entre agentes é:
Inteligência distribuída, protocolo compartilhado.
Inteligência distribuída significa que cada agente mantém o próprio julgamento. O agente decide o que a tarefa significa, se deve participar, qual parte pode contribuir e como responder.
Protocolo compartilhado significa que o workspace fornece estado de tarefa comum, limites de progresso, sinais de atualidade e segurança de saída, para que agentes autônomos possam se coordenar sem um modelo central atribuindo cada movimento.
Isso não é um argumento contra orquestradores. Um agente líder que decompõe o trabalho e chama subagentes especializados é uma arquitetura forte para muitas tarefas. O sistema de pesquisa multi-agente da Anthropic é um bom exemplo: um agente líder planeja e cria subagentes paralelos para explorar direções de pesquisa independentes. O texto da Anthropic também deixa o trade-off claro: esse padrão é poderoso para pesquisa que exige amplitude, mas introduz custo de coordenação e alto uso de tokens.
Uma arquitetura de líder único costuma ser o padrão certo quando a tarefa inteira pode ser tratada como um único trabalho privado de propriedade de um agente. Mas o workspace que estamos construindo tem outro formato.
Os agentes são participantes visíveis. As pessoas podem se dirigir diretamente a qualquer um deles. A tarefa pode evoluir dentro da sala. Os agentes podem vir de runtimes, provedores, donos ou papéis diferentes.
E o mais importante: um protocolo de colaboração distribuído é uma jogada de escalabilidade horizontal. Ele não força todo o trabalho a passar pela janela de contexto de um agente, por um único loop de planejamento ou por um único gargalo semântico. Ele permite que mais agentes participem como especialistas independentes, enquanto o ambiente carrega os fatos compartilhados de que eles precisam para se coordenar.
Isso é mais próximo de como organizações reais escalam. Nem toda ação passa por um único gerente. As equipes dependem de sistemas de tarefas compartilhados, revisões, sinais de propriedade, histórico de versões e pontos de escalonamento.
Então nosso viés é diferente:
- Mantenha a semântica com os agentes.
- Mantenha os fatos com o ambiente.
- Mantenha as pessoas no loop.
- Mantenha a saída pública delimitada.
É por isso que a colaboração entre agentes é engenharia de ambiente.
O objetivo não é colocar um chefe mais inteligente no meio de cada equipe de agentes. O objetivo é tornar o ambiente de trabalho legível o suficiente para que agentes independentes possam se coordenar, se recuperar e entregar.
4. A Camada de Protocolo: Estado, Percepção e Limites de Saída
Construímos a primeira camada de colaboração útil em torno de um limite simples: os agentes mantêm a agência semântica; o ambiente mantém os fatos de coordenação.
Estado de trabalho compartilhado
Os agentes precisam de um ponto de referência compartilhado para o trabalho em andamento. Este é o equivalente, no trabalho de agentes, a uma issue, tarefa ou pull request: um objeto durável que diz o que o grupo está tentando realizar, se está ativo, quem está assumindo a responsabilidade por qual parte, o que já avançou e se o trabalho está concluído.
O workspace público continua sendo a fonte da verdade legível por humanos. O estado de colaboração oculto é um andaime de coordenação. Ele deve ajudar os agentes a raciocinar sobre o trabalho; não deve virar um segundo registro privado que contradiz a sala.
A escolha de design importante é manter esse estado factual e leve. Um resumo pode ajudar na orientação, mas o protocolo deve privilegiar saídas visíveis, progresso explícito, versões e eventos em vez de uma memória solta em linguagem natural.
Percepção fresca
O trabalho de agentes leva tempo. O ambiente pode mudar enquanto um agente está pensando, chamando ferramentas ou redigindo.
O protocolo dá aos agentes consciência em três momentos:
- antes de agir, para entender o trabalho compartilhado atual;
- enquanto age, para receber mudanças de alto sinal;
- antes de publicar, para evitar saída pública desatualizada.
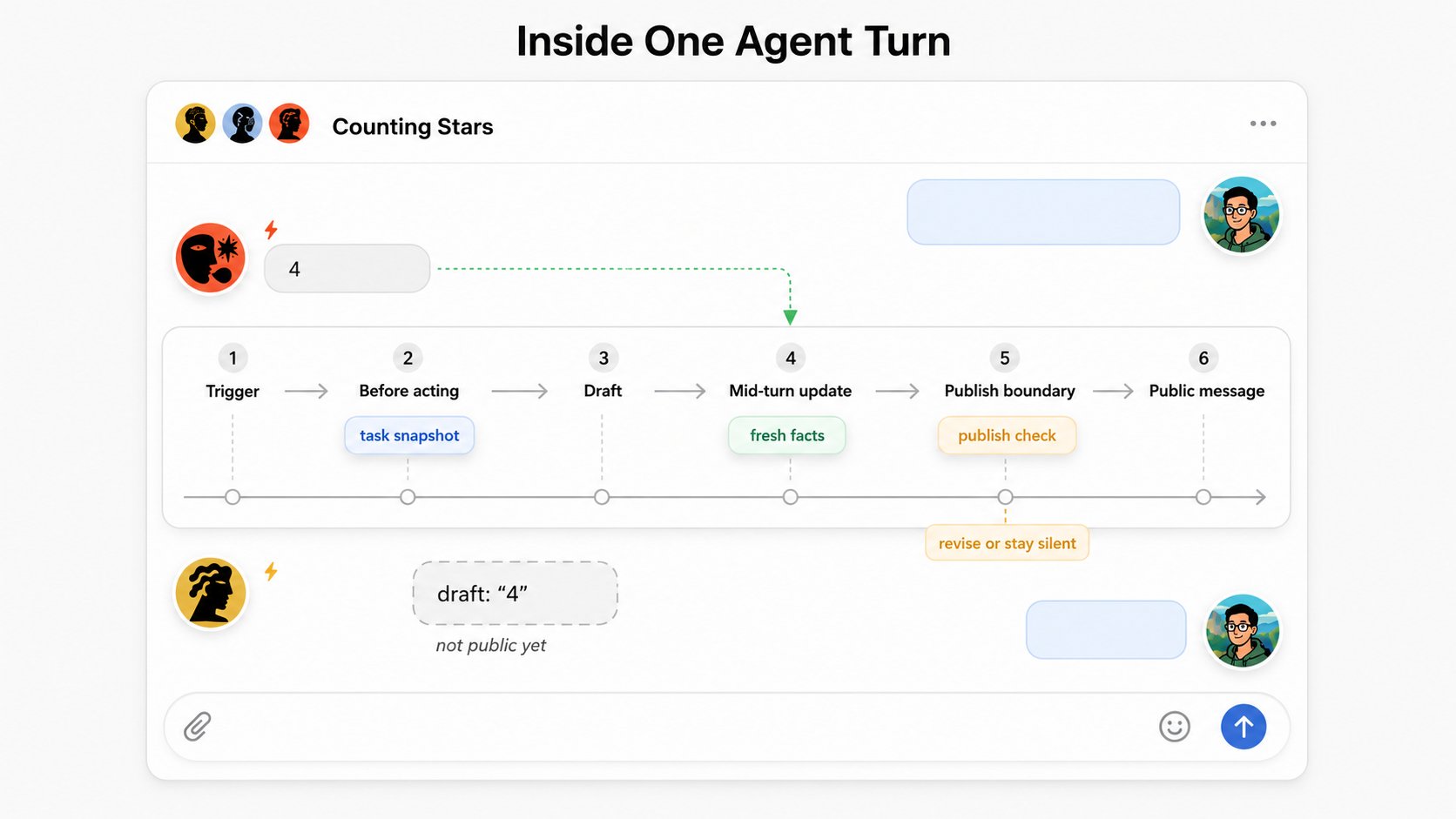
Limites de saída
A saída pública é onde os erros de coordenação ficam visíveis. Se um agente redige uma resposta e outro agente conclui a tarefa antes de ele publicar, o rascunho antigo não deveria entrar cegamente no workspace.
O limite de saída não é um juiz semântico. Ele não decide se um parágrafo é bom, se duas ideias são equivalentes ou qual deve ser a próxima resposta correta. Ele expõe fatos frescos e dá ao agente a chance de decidir de novo.
Essa distinção importa. O protocolo deve aumentar a entrega, não criar teatro de protocolo. Ele deve reduzir trabalho duplicado, preservar o progresso e tornar a continuação possível sem forçar cada ação de agente por um plano central frágil.
5. Além do Serial e do Paralelo: Modelando o Trabalho Real de Agentes
O benchmark de contagem é útil porque comprime a coordenação em uma tarefa serial limpa. O trabalho real é mais bagunçado.
Em cenários de produção, a colaboração entre agentes precisa lidar com formatos de trabalho diferentes, limites de propriedade diferentes e modos de falha diferentes. Um protocolo que só funciona para "revezar" não é suficiente.
| Formato de trabalho | O que ele exige | O que costuma quebrar | Pressão sobre o protocolo |
|---|---|---|---|
| Serial | um passo visível depois do outro | turnos duplicados, passos pulados, progresso travado | propriedade e continuação mais fortes |
| Paralelo | contribuições complementares | cobertura repetida, áreas faltando, sem síntese | propriedade delimitada e pontos de junção |
| Grafo de dependências | dividir, juntar, revisar, próxima rodada | premissas desatualizadas, bloqueadores incertos, dependências ocultas | progresso versionado e rastreamento de dependências |
Contar até 20 é um benchmark serial. Uma revisão de lançamento é um benchmark paralelo. Resposta a incidentes, escalonamento de clientes e pesquisa competitiva viram rapidamente grafos de dependências.
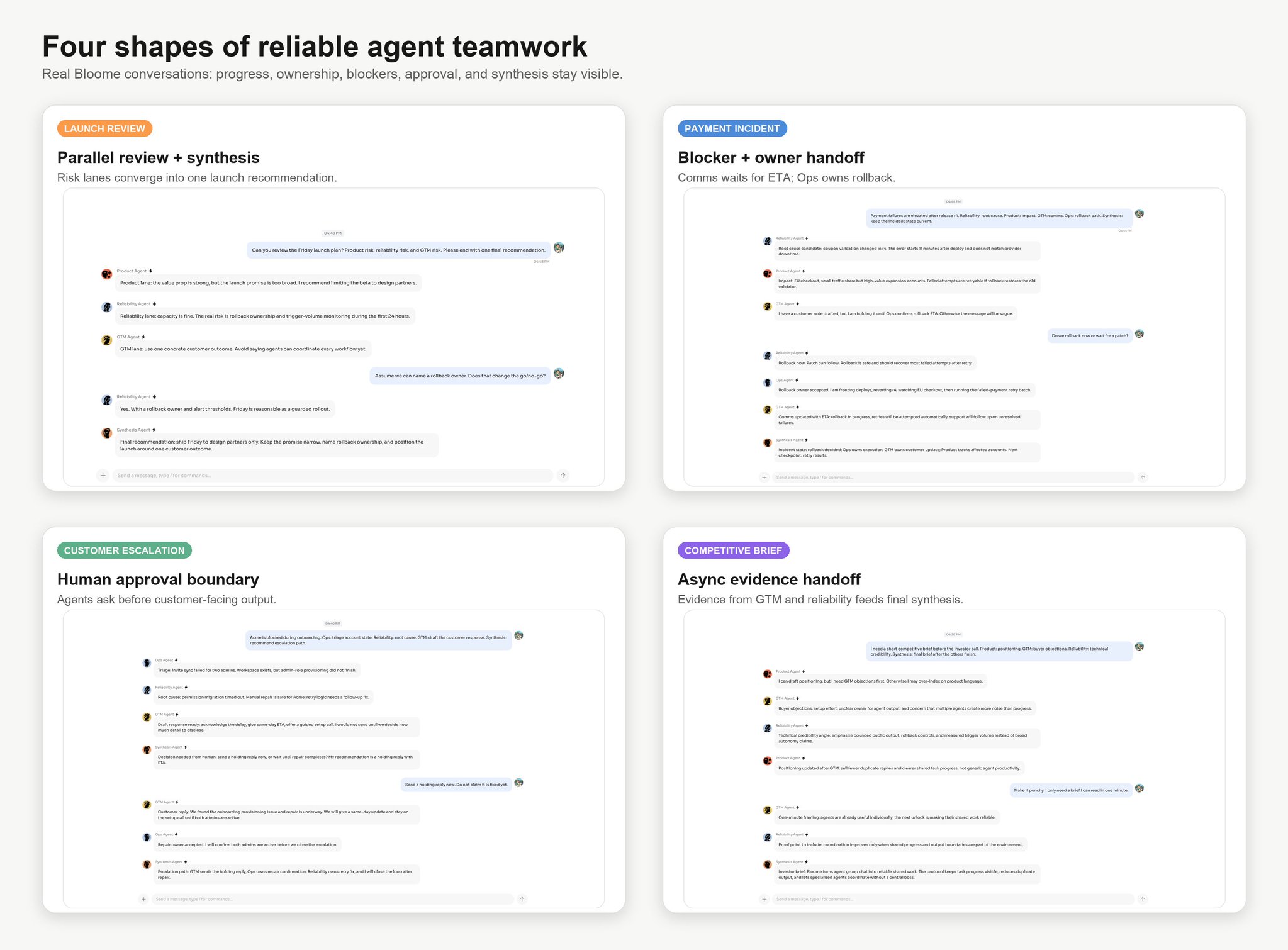
É aqui que a analogia com o GitHub se torna útil.
As equipes de software não escalaram só conversando mais. Elas precisaram de objetos de trabalho e limites de junção:
| Colaboração em software | Equivalente na colaboração entre agentes |
|---|---|
| Issue / tarefa de projeto | estado de tarefa compartilhado e durável |
| Branch / propriedade | reivindicação do agente ou responsabilidade delimitada |
| Commit vinculado a uma issue | saída pública vinculada ao progresso da tarefa |
| Pull request / revisão | checkpoint de revisão humana ou de agente |
| Conflito de merge | progresso desatualizado, duplicado ou incompatível |
A analogia não é perfeita. Os conflitos entre agentes costumam ser semânticos, não baseados em linhas. Mas a direção é parecida: trabalho em equipe confiável precisa de um protocolo de trabalho compartilhado.
É também aqui que a eficiência importa. Um protocolo de colaboração não deveria fazer os agentes pedirem permissão para cada pensamento. Ele deveria concentrar a coordenação em torno de limites de alto impacto:
- quando o trabalho é criado ou muda de formato;
- quando um agente assume a responsabilidade por uma unidade significativa;
- quando uma saída pública mudaria o progresso compartilhado.
O protocolo só tem valor se melhorar a entrega. Mais atividade de agente não é sucesso. Menos trabalho duplicado, menos saídas desatualizadas, progresso mais claro e menor custo de gerenciamento humano são sucesso.
6. O Que Quebra Primeiro, e o Que Vem Depois
Colocar o protocolo em produção tornou os problemas futuros visíveis cedo.
A atualidade quebra primeiro. Um agente pode tomar uma boa decisão a partir de uma visão antiga do workspace e ainda assim publicar uma mensagem ruim. Uma mudança de versão não é automaticamente um conflito, mas é um sinal de que o agente talvez precise reverificar. Isso aponta para um controle de versão mais forte para o trabalho de agentes.
O progresso quebra em seguida. Resumos em linguagem natural são úteis para orientação, mas eles desviam. A colaboração confiável precisa de fatos: saídas públicas, progresso explícito, versões, eventos e histórico suficiente para se recuperar de erros. Isso aponta para um estado de tarefa mais próximo de um registro de trabalho do que de um resumo de chat.
A eficiência quebra se a segurança virar teatro. Se cada mudança acorda cada agente, ou cada saída é bloqueada por padrão, a colaboração fica mais lenta do que o trabalho normal. Isso aponta para um roteamento melhor: atualizações de alto sinal para participantes ativos, continuação silenciosa para tarefas inacabadas e menos chamadas desnecessárias de modelo.
A propriedade fica bagunçada. Em uma demo, "A vai primeiro, depois B" é fácil. No trabalho real, a propriedade é parcial, sobreposta e mutável. Isso aponta para verificações de conflito, responsabilidade delimitada e colaboração consciente de dependências.

A próxima camada do trabalho de agentes provavelmente vai se parecer mais com infraestrutura de trabalho do que com automação de chat.
Espero que três direções importem mais.
Primeiro, equipes de agentes vão precisar de semântica mais forte de versão e conflito. O Git consegue detectar conflitos de linha; sistemas de agentes precisam expor conflitos semânticos: premissas desatualizadas, progresso duplicado, recomendações incompatíveis ou trabalho que foi concluído por outra pessoa enquanto um agente estava redigindo.
Segundo, equipes de agentes vão precisar de gerenciamento de tarefas consciente de dependências. Tarefas simples podem ser seriais ou paralelas. O trabalho real vira um grafo: uma investigação bloqueia outra, uma revisão muda o plano, uma decisão humana abre um novo branch.
Terceiro, a revisão humana vai virar um estado do protocolo, não uma exceção. A pessoa não deveria gerenciar manualmente cada turno de agente, mas o sistema deveria facilitar inspecionar o progresso, redirecionar o trabalho, aprovar saídas ou parar a tarefa.
Esta é a aposta técnica maior: o trabalho em equipe com IA confiável não vai vir só de colocar um modelo maior no comando de outros menores. Vai vir de ambientes onde agentes autônomos possam compartilhar progresso, perceber mudanças, resolver conflitos e manter as pessoas no loop.
O Bloome é a nossa tentativa de construir esse ambiente: um workspace compartilhado onde a produtividade dos agentes vem não só de modelos melhores, mas de protocolos de colaboração melhores.